
Documentación de APIs
Todo lo que necesitas para integrar nuestras APIs de Inteligencia Artificial en tus proyectos. Encuentra guías, ejemplos de código y referencias completas.
Todo lo que necesitas para integrar nuestras APIs de Inteligencia Artificial en tus proyectos. Encuentra guías, ejemplos de código y referencias completas.

Si no encuentras la respuesta en nuestra documentación o FAQs, no dudes en ponerte en contacto con nuestro equipo de soporte.
La información y ejemplos de código proporcionados en esta documentación tienen fines ilustrativos y educativos. Aunque nos esforzamos por mantener la documentación actualizada y precisa, Apisdom no garantiza que el contenido esté libre de errores ni que sea adecuado para todos los casos de uso. El uso de nuestras APIs y la implementación de los ejemplos es responsabilidad del desarrollador. Para información sobre términos de uso, privacidad y condiciones del servicio, consulta nuestra página legal.
IA Profesional. Integración Simple. Resultados Reales.
Bienvenido a la documentación oficial de las APIs de ApisDom. Aquí encontrarás todo lo necesario para integrar nuestros servicios de inteligencia artificial en tus aplicaciones.
| API | Descripción | Modelo |
|---|---|---|
| 🎭 [Sentiment API] | Detecta emociones en texto (positivo/negativo) | DistilBERT (SST-2) |
| 🛡️ [Moderation API] | Identifica contenido tóxico e inapropiado | Toxic-BERT (Jigsaw) |
| 📈 [Prediction API] | Predicciones de series temporales | Chronos-2 (Amazon) |
| ⚡ [Recommendations API] | Recomendaciones personalizadas por similitud semántica | all-MiniLM-L6-v2 |
Tu panel de usuario:
▶ Ver recorrido: Panel de Usuariocurl -X POST "https://apisdom.com/api/v1/sentiment" \
-H "X-API-Key: TU_API_KEY_AQUI" \
-H "Content-Type: application/json" \
-d '{"text": "This product is amazing!"}'
La respuesta es ANIDADA con dos objetos principales: _metadata y response.
{
"_metadata": {
"provider": "ApisDom",
"tagline": "Inteligencia artificial transparente",
"website": "https://apisdom.com",
"timestamp": "2026-01-21T10:00:00.000Z",
"service": "Sentiment Analysis",
"channel": "ApisDom Platform",
"request_id": "sent_1768954704623_abc123",
"documentation": "https://apisdom.com/documentacion"
},
"response": {
"text": "This product is amazing!",
"sentiment": "positive",
"score": 0.9721,
"warning": null,
"info_message": null
}
}
⚠️ Importante: Todas las APIs devuelven esta estructura anidada. Accede a los datos mediante
resultado['response']oresultado.response.
Todas las APIs requieren tu API Key en el header X-API-Key:
X-API-Key: tu_api_key_aqui
Consulta los planes disponibles y precios actualizados en: apisdom.com/pricing
La API devuelve headers que te permiten controlar tu consumo programáticamente:
| Header | Descripción |
|---|---|
X-RateLimit-Limit | Tu límite de peticiones por minuto |
X-RateLimit-Remaining | Peticiones restantes en la ventana actual |
Retry-After | Segundos a esperar si recibes 429 |
Para optimizar costes, los microservicios de IA escalan a cero cuando no hay actividad.
💡 Nota: La primera petición puede tardar ~20 segundos mientras el servicio arranca. Las peticiones siguientes serán < 500ms mientras el servicio permanezca activo.
| Código | Estado | Significado | Solución |
|---|---|---|---|
200 | ✅ Éxito | Todo correcto | Procesar respuesta |
400 | ❌ Request inválido | Formato JSON incorrecto | Revisar parámetros enviados |
401 | 🔒 No autorizado | API Key inválida o revocada | Verificar API Key en dashboard |
402 | 💳 Sin créditos | Créditos agotados | Consultar planes |
422 | ❌ Datos inválidos | Campos requeridos faltantes | Revisar campos requeridos |
429 | ⏱️ Rate limit | Límite de peticiones excedido | Esperar según Retry-After |
500 | 🔥 Error servidor | Error interno | Reintentar en 30s |
{
"detail": "Créditos insuficientes. Consulta planes en apisdom.com/pricing"
}
Cada API expone un endpoint de health check (sin autenticación):
| API | Endpoint |
|---|---|
| Sentiment | GET https://apisdom.com/api/v1/sentiment |
| Moderation | GET https://apisdom.com/api/v1/moderacion |
| Prediction | GET https://apisdom.com/api/v1/predictions |
| Recommendations | GET https://apisdom.com/api/v1/recommendations/health |
{
"status": "healthy",
"service": "sentiment",
"valid": true,
"timestamp": "2026-01-21T10:00:00.000Z",
"provider": "ApisDom"
}
| API | Campo | Límite |
|---|---|---|
| Sentiment | text | 1-5,000 caracteres |
| Moderation | text | 1-5,000 caracteres |
| Prediction | dates / values | 10-5,000 puntos |
| Prediction | periods | 1-365 días |
| Recommendations | query | 3-500 caracteres |
| Recommendations | contents | 1-100 items (máx 1,000 chars/item) |
| Recommendations | top_k | 1-20 resultados |
Nota: Los modelos BERT procesan máximo 512 tokens. Textos más largos serán truncados y recibirás un
warningen la respuesta.
import requests
API_URL = "https://apisdom.com/api/v1/sentiment"
API_KEY = "tu_api_key_aqui"
def analizar_sentimiento(texto):
response = requests.post(
API_URL,
headers={
"X-API-Key": API_KEY,
"Content-Type": "application/json"
},
json={"text": texto}
)
response.raise_for_status()
return response.json()
# Uso
resultado = analizar_sentimiento("This product is excellent!")
# IMPORTANTE: Acceder al objeto 'response' anidado
datos = resultado['response']
print(f"Sentimiento: {datos['sentiment']}")
print(f"Confianza: {datos['score']:.0%}")
print(f"Request ID: {resultado['_metadata']['request_id']}")
# Output:
# Sentimiento: positive
# Confianza: 97%
# Request ID: sent_1768954704623_abc123
const API_URL = 'https://apisdom.com/api/v1/moderacion';
const API_KEY = 'tu_api_key_aqui';
async function moderarContenido(texto) {
const response = await fetch(API_URL, {
method: 'POST',
headers: {
'X-API-Key': API_KEY,
'Content-Type': 'application/json'
},
body: JSON.stringify({ text: texto })
});
if (!response.ok) throw new Error(`HTTP ${response.status}`);
return response.json();
}
// Uso
const resultado = await moderarContenido('Thank you for your help!');
// IMPORTANTE: Acceder al objeto 'response' anidado
const datos = resultado.response;
console.log(`Es tóxico: ${datos.is_toxic}`);
console.log(`Score: ${(datos.toxicity_score * 100).toFixed(0)}%`);
// Output:
// Es tóxico: false
// Score: 2%
curl -X POST "https://apisdom.com/api/v1/predictions" \
-H "X-API-Key: tu_api_key_aqui" \
-H "Content-Type: application/json" \
-d '{
"dates": ["2024-01-01","2024-01-02","2024-01-03","2024-01-04","2024-01-05",
"2024-01-06","2024-01-07","2024-01-08","2024-01-09","2024-01-10"],
"values": [100,105,102,108,115,112,120,118,125,130],
"periods": 5
}'
# La respuesta incluye _metadata y response anidados
curl -X POST "https://apisdom.com/api/v1/recommendations" \
-H "X-API-Key: tu_api_key_aqui" \
-H "Content-Type: application/json" \
-d '{
"query": "machine learning tutorials",
"contents": [
"Python ML basics for beginners",
"JavaScript introduction and syntax",
"Deep Learning with PyTorch guide",
"Data Science with pandas",
"React frontend development"
],
"top_k": 3
}'
# Respuesta: Lista de contenidos ordenados por similitud semántica
Este código maneja TODOS los casos de error reales que puede devolver la API:
import time
import requests
from typing import Any
class ApisDomClient:
"""
Cliente robusto para APIs de ApisDom.
Maneja: retry, backoff exponencial, rate limit, sin créditos.
"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
self.session.headers.update({
"X-API-Key": api_key,
"Content-Type": "application/json"
})
self.base_url = "https://apisdom.com/api/v1"
def _request_with_retry(
self,
method: str,
endpoint: str,
json_data: dict | None = None,
max_retries: int = 3
) -> dict[str, Any]:
"""Ejecuta request con reintentos y manejo de errores."""
url = f"{self.base_url}/{endpoint}"
for attempt in range(max_retries):
try:
response = self.session.request(
method, url, json=json_data, timeout=30
)
# Éxito
if response.status_code == 200:
return response.json()
# Sin créditos - no reintentar
if response.status_code == 402:
raise CreditosInsuficientesError(
"Sin créditos. Consulta planes en: https://apisdom.com/pricing"
)
# API Key inválida - no reintentar
if response.status_code == 401:
raise ApiKeyInvalidaError(
"API Key inválida. Verifica en tu Dashboard."
)
# Rate limit - esperar y reintentar
if response.status_code == 429:
retry_after = int(response.headers.get("Retry-After", 60))
print(f"Rate limit. Esperando {retry_after}s...")
time.sleep(retry_after)
continue
# Error servidor - backoff exponencial
if response.status_code >= 500:
wait_time = (2 ** attempt) * 1
print(f"Error {response.status_code}. Retry en {wait_time}s...")
time.sleep(wait_time)
continue
response.raise_for_status()
except requests.exceptions.Timeout:
if attempt < max_retries - 1:
wait_time = (2 ** attempt) * 2
print(f"Timeout. Retry en {wait_time}s...")
time.sleep(wait_time)
continue
raise
raise Exception(f"Falló después de {max_retries} intentos")
def analizar_sentimiento(self, texto: str) -> dict:
"""Analiza el sentimiento de un texto."""
result = self._request_with_retry("POST", "sentiment", {"text": texto})
return result['response'] # Devuelve solo los datos útiles
def moderar_contenido(self, texto: str) -> dict:
"""Modera contenido para detectar toxicidad."""
result = self._request_with_retry("POST", "moderacion", {"text": texto})
return result['response']
def predecir_serie(
self,
dates: list[str],
values: list[float],
periods: int = 7
) -> dict:
"""Predice valores futuros de una serie temporal."""
result = self._request_with_retry(
"POST",
"predictions",
{"dates": dates, "values": values, "periods": periods}
)
return result['response']
def obtener_recomendaciones(
self,
query: str,
contents: list[str],
top_k: int = 5
) -> dict:
"""Genera recomendaciones personalizadas por similitud semántica."""
result = self._request_with_retry(
"POST",
"recommendations",
{"query": query, "contents": contents, "top_k": top_k}
)
return result['response']
class CreditosInsuficientesError(Exception):
"""Error cuando no hay créditos disponibles."""
pass
class ApiKeyInvalidaError(Exception):
"""Error cuando la API Key es inválida o está revocada."""
pass
# Ejemplo de uso
if __name__ == "__main__":
client = ApisDomClient("tu_api_key_aqui")
# Sentiment
sentiment = client.analizar_sentimiento("This product is great!")
print(f"Sentimiento: {sentiment['sentiment']} ({sentiment['score']:.0%})")
# Moderation
moderation = client.moderar_contenido("Thank you for your help!")
print(f"Es tóxico: {moderation['is_toxic']}")
# Recommendations
recommendations = client.obtener_recomendaciones(
query="machine learning tutorials",
contents=[
"Python ML basics",
"JavaScript intro",
"Deep Learning with PyTorch"
],
top_k=3
)
print(f"Top recomendación: {recommendations['results'][0]['item']}")
Antes de ir a producción, verifica que tu aplicación:
| Elemento | Descripción |
|---|---|
☐ Maneja 401 | Redirige a login o muestra error de API Key |
☐ Maneja 402 | Muestra mensaje "Sin créditos" en UI |
☐ Maneja 429 | Implementa retry con header Retry-After |
☐ Maneja 500 | Implementa retry con backoff exponencial |
☐ Accede a response | Usa resultado['response'] para los datos |
| ☐ API Key segura | No expuesta en código público |
| ☐ Cachea resultados | Opcional, ahorra créditos en llamadas idénticas |
☐ Revisa warning | Verifica truncamiento en textos largos |
warning en las respuestas| API | Documentación |
|---|---|
| 🎭 Sentiment | [SENTIMENT] - Guía completa |
| 🛡️ Moderation | [MODERATION]- Guía completa |
| 📈 Prediction | [PREDICTION] - Guía completa |
| ⚡ Recommendations | [RECOMMENDATIONS] - Guía completa |
Última actualización de documentación: Abril 2026
ApisDom · Inteligencia Artificial Transparente
Detecta automáticamente si un texto expresa emociones positivas o negativas utilizando el modelo DistilBERT (fine-tuned en SST-2).
✅ Análisis de Reviews de productos (E-commerce)
✅ Feedback de clientes (Quejas vs Felicitaciones)
✅ Moderación de comentarios polarizados
❌ Clasificación de noticias o hechos objetivos
❌ Detección de sarcasmo sutil
❌ Textos que requieran clasificación "neutral"
| Propiedad | Valor |
|---|---|
| URL Base | https://apisdom.com/api/v1 |
| Método | POST |
| Autenticación | API Key (Header X-API-Key) |
| Tipo de Crédito | text |
| Coste por llamada | 1 crédito |
| Modelo IA | DistilBERT (fine-tuned en SST-2 - binario: solo positive/negative) |
| Límite de tokens | 512 tokens (textos largos serán truncados) |
| Datos de entrenamiento | Stanford Sentiment Treebank (SST-2) - Solo reseñas de cine |
La API devuelve headers que te permiten controlar tu consumo:
| Header | Descripción |
|---|---|
X-RateLimit-Limit | Tu límite de peticiones por minuto |
X-RateLimit-Remaining | Peticiones restantes en la ventana actual |
Retry-After | Segundos a esperar si recibes 429 |
Para optimizar costes, los microservicios de IA escalan a cero cuando no hay actividad.
💡 Nota: La primera petición puede tardar más de lo normal mientras el servicio arranca. Las peticiones siguientes serán mucho más rápidas mientras el servicio permanezca activo.
Consulta los planes disponibles y precios actualizados en: apisdom.com/pricing
Todas las peticiones requieren tu API Key en el header X-API-Key:
X-API-Key: tu_api_key_aqui
Puedes obtener tu API Key desde el panel de usuario en apisdom.com/dashboard.
POST https://apisdom.com/api/v1/sentiment
| Campo | Tipo | Requerido | Descripción |
|---|---|---|---|
text | string | ✅ Sí | Texto a analizar. Mínimo 1 carácter, máximo 5000. |
{
"text": "Este producto es absolutamente increíble. La calidad supera todas mis expectativas y el envío fue rapidísimo. ¡Muy recomendado!"
}
La respuesta es ANIDADA con dos objetos principales: _metadata y response.
{
"_metadata": {
"provider": "ApisDom",
"tagline": "Inteligencia artificial transparente",
"website": "https://apisdom.com",
"timestamp": "2026-01-21T10:00:00.000Z",
"service": "Sentiment Analysis",
"channel": "ApisDom Platform",
"request_id": "sent_1768954704623_4cj49l3",
"documentation": "https://apisdom.com/documentacion"
},
"response": {
"text": "Este producto es absolutamente increíble. La calidad supera todas mis expectativas y el envío fue rapidísimo. ¡Muy recomendado!",
"sentiment": "positive",
"score": 0.9847,
"warning": null,
"info_message": null
}
}
Nivel Raíz:
| Campo | Tipo | Descripción |
|---|---|---|
_metadata | object | Información del proveedor y tracking de la petición |
response | object | El resultado del análisis de sentimiento |
Dentro de _metadata:
| Campo | Tipo | Descripción |
|---|---|---|
provider | string | Siempre "ApisDom" |
timestamp | string | Timestamp ISO 8601 de la petición |
request_id | string | Identificador único de esta petición |
service | string | Nombre del servicio ("Sentiment Analysis") |
channel | string | Canal de distribución ("ApisDom Platform") |
Dentro de response:
| Campo | Tipo | Descripción |
|---|---|---|
text | string | El texto que fue analizado |
sentiment | string | Sentimiento detectado: positive o negative únicamente (modelo binario) |
score | float | Confianza del modelo (0.0 a 1.0). Cuanto más cercano a 1, mayor certeza. |
warning | string | null | Aviso si el texto fue truncado (textos muy largos) |
info_message | string | null | Información adicional sobre el análisis |
⚠️ Importante: El campo sentiment SOLO devolverá
positiveonegative. Este es un modelo de clasificación binaria entrenado con reseñas de cine (SST-2). No existe clase "neutral" nativa.
import requests
API_URL = "https://apisdom.com/api/v1/sentiment"
API_KEY = "tu_api_key_aqui"
def analizar_sentimiento(texto):
"""
Analiza el sentimiento de un texto.
Args:
texto: String con el texto a analizar (máx 5000 caracteres)
Returns:
dict con _metadata y response conteniendo sentiment, score y detalles
"""
response = requests.post(
API_URL,
headers={
"X-API-Key": API_KEY,
"Content-Type": "application/json"
},
json={"text": texto}
)
if response.status_code == 200:
return response.json()
elif response.status_code == 402:
raise Exception("Sin créditos. Consulta planes en apisdom.com/pricing")
else:
raise Exception(f"Error: {response.status_code} - {response.text}")
# Ejemplo de uso
resultado = analizar_sentimiento("Me encanta este servicio, funciona perfecto!")
# IMPORTANTE: Acceder a los datos dentro del objeto 'response'
datos = resultado['response']
print(f"Sentimiento: {datos['sentiment']}")
print(f"Confianza: {datos['score']:.2%}")
print(f"Request ID: {resultado['_metadata']['request_id']}")
# Output:
# Sentimiento: positive
# Confianza: 97.32%
# Request ID: sent_1768954704623_4cj49l3
const API_URL = 'https://apisdom.com/api/v1/sentiment';
const API_KEY = 'tu_api_key_aqui';
async function analizarSentimiento(texto) {
/**
* Analiza el sentimiento de un texto.
* @param {string} texto - Texto a analizar (máx 5000 caracteres)
* @returns {Promise<Object>} - Resultado con _metadata y response
*/
const response = await fetch(API_URL, {
method: 'POST',
headers: {
'X-API-Key': API_KEY,
'Content-Type': 'application/json'
},
body: JSON.stringify({ text: texto })
});
if (response.status === 402) {
throw new Error('Sin créditos. Consulta planes en apisdom.com/pricing');
}
if (!response.ok) {
throw new Error(`Error: ${response.status}`);
}
return response.json();
}
// Ejemplo de uso
analizarSentimiento('El producto llegó roto y nadie me ayuda')
.then(resultado => {
// IMPORTANTE: Acceder al objeto 'response' anidado
const datos = resultado.response;
console.log(`Sentimiento: ${datos.sentiment}`);
console.log(`Confianza: ${(datos.score * 100).toFixed(2)}%`);
console.log(`Request ID: ${resultado._metadata.request_id}`);
// Output:
// Sentimiento: negative
// Confianza: 94.56%
// Request ID: sent_1768954704623_4cj49l3
})
.catch(console.error);
curl -X POST "https://apisdom.com/api/v1/sentiment" \
-H "X-API-Key: tu_api_key_aqui" \
-H "Content-Type: application/json" \
-d '{"text": "La atención al cliente fue excelente, resolvieron mi problema en minutos."}'
# La respuesta incluye _metadata y response anidados:
# {
# "_metadata": { "provider": "ApisDom", "request_id": "...", ... },
# "response": { "sentiment": "positive", "score": 0.9847, ... }
# }
<?php
$api_url = 'https://apisdom.com/api/v1/sentiment';
$api_key = 'tu_api_key_aqui';
function analizarSentimiento($texto) {
global $api_url, $api_key;
$ch = curl_init($api_url);
curl_setopt_array($ch, [
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POST => true,
CURLOPT_HTTPHEADER => [
'X-API-Key: ' . $api_key,
'Content-Type: application/json'
],
CURLOPT_POSTFIELDS => json_encode(['text' => $texto])
]);
$response = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
if ($httpCode === 402) {
throw new Exception('Sin créditos. Consulta planes en apisdom.com/pricing');
}
return json_decode($response, true);
}
// Ejemplo de uso
$resultado = analizarSentimiento('El servicio técnico tardó mucho pero al final lo solucionaron');
// IMPORTANTE: Acceder al objeto 'response' anidado
$datos = $resultado['response'];
echo "Sentimiento: " . $datos['sentiment'] . "\n";
echo "Confianza: " . number_format($datos['score'] * 100, 2) . "%\n";
echo "Request ID: " . $resultado['_metadata']['request_id'] . "\n";
// Output:
// Sentimiento: positive
// Confianza: 62.18%
// Request ID: sent_1768954704623_4cj49l3
?>
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Text.Json.Serialization;
public class SentimentApiClient
{
private readonly HttpClient _client;
private const string API_URL = "https://apisdom.com/api/v1/sentiment";
public SentimentApiClient(string apiKey)
{
_client = new HttpClient();
_client.DefaultRequestHeaders.Add("X-API-Key", apiKey);
}
public async Task<SentimentApiResponse> AnalizarSentimientoAsync(string texto)
{
var content = new StringContent(
JsonSerializer.Serialize(new { text = texto }),
Encoding.UTF8,
"application/json"
);
var response = await _client.PostAsync(API_URL, content);
if (response.StatusCode == System.Net.HttpStatusCode.PaymentRequired)
{
throw new Exception("Sin créditos. Consulta planes en apisdom.com/pricing");
}
response.EnsureSuccessStatusCode();
var json = await response.Content.ReadAsStringAsync();
return JsonSerializer.Deserialize<SentimentApiResponse>(json);
}
}
// IMPORTANTE: La respuesta es ANIDADA - necesitas estas clases
public class SentimentApiResponse
{
[JsonPropertyName("_metadata")]
public SentimentMetadata Metadata { get; set; }
[JsonPropertyName("response")]
public SentimentResult Response { get; set; }
}
public class SentimentMetadata
{
[JsonPropertyName("provider")]
public string Provider { get; set; }
[JsonPropertyName("request_id")]
public string RequestId { get; set; }
[JsonPropertyName("timestamp")]
public string Timestamp { get; set; }
}
public class SentimentResult
{
[JsonPropertyName("text")]
public string Text { get; set; }
[JsonPropertyName("sentiment")]
public string Sentiment { get; set; }
[JsonPropertyName("score")]
public double Score { get; set; }
[JsonPropertyName("warning")]
public string? Warning { get; set; }
[JsonPropertyName("info_message")]
public string? InfoMessage { get; set; }
}
// Ejemplo de uso
var client = new SentimentApiClient("tu_api_key_aqui");
var apiResponse = await client.AnalizarSentimientoAsync("¡Producto de primera calidad!");
// Acceder a los datos dentro del objeto Response
Console.WriteLine($"Sentimiento: {apiResponse.Response.Sentiment}");
Console.WriteLine($"Confianza: {apiResponse.Response.Score:P2}");
Console.WriteLine($"Request ID: {apiResponse.Metadata.RequestId}");
// Output:
// Sentimiento: positive
// Confianza: 99.99%
// Request ID: sent_1768954865380_hh3t7b1
reseñas = [
"Excelente relación calidad-precio",
"Llegó tarde y con el embalaje dañado",
"Hace lo que promete, nada más",
]
for reseña in reseñas:
api_result = analizar_sentimiento(reseña)
# Acceder al objeto 'response' anidado
datos = api_result['response']
print(f"'{reseña[:30]}...' → {datos['sentiment']} ({datos['score']:.0%})")
# Output (nota: el modelo tiende a alta confianza):
# 'Excelente relación calidad-pr...' → positive (99%)
# 'Llegó tarde y con el embalaje...' → negative (99%)
# 'Hace lo que promete, nada más...' → positive (87%)
# ⚠️ Nota: textos "neutros" suelen clasificarse como positive debido al modelo binario
def priorizar_ticket(mensaje):
"""Asigna prioridad según el sentimiento del cliente."""
api_result = analizar_sentimiento(mensaje)
# Acceder al objeto 'response' anidado
resultado = api_result['response']
if resultado['sentiment'] == 'negative' and resultado['score'] > 0.8:
return "🔴 URGENTE - Cliente muy insatisfecho"
elif resultado['sentiment'] == 'negative':
return "🟡 ALTA - Cliente insatisfecho"
else:
return "🟢 NORMAL"
ticket = "Llevo 3 días esperando respuesta y nadie me ayuda. Es inaceptable."
print(priorizar_ticket(ticket))
# Output: 🔴 URGENTE - Cliente muy insatisfecho
async function actualizarDashboard(comentarios) {
const apiResults = await Promise.all(
comentarios.map(c => analizarSentimiento(c))
);
// Extraer el objeto 'response' de cada resultado de la API
const resultados = apiResults.map(r => r.response);
const stats = {
positivos: resultados.filter(r => r.sentiment === 'positive').length,
negativos: resultados.filter(r => r.sentiment === 'negative').length,
promedioConfianza: resultados.reduce((a, b) => a + b.score, 0) / resultados.length
};
console.log('📊 Resumen de Satisfacción:');
console.log(` ✅ Positivos: ${stats.positivos}`);
console.log(` ❌ Negativos: ${stats.negativos}`);
console.log(` 📊 Confianza promedio: ${(stats.promedioConfianza * 100).toFixed(1)}%`);
return stats;
}
| Código | Significado | Solución |
|---|---|---|
400 | Texto inválido (vacío o muy largo) | Asegúrate de enviar entre 1 y 5000 caracteres |
401 | API Key inválida | Verifica tu API Key en el dashboard |
402 | Sin créditos disponibles | Consulta planes en apisdom.com/pricing |
429 | Límite de peticiones excedido | Espera antes de reintentar (ver headers de rate limit) |
500 | Error interno del servidor | Reintenta en unos segundos. Si persiste, contacta soporte |
Política de ApisDom: Creemos que los desarrolladores merecen saber exactamente cómo funcionan las APIs que usan. Esta sección documenta los detalles técnicos verificados directamente del código fuente.
Tu texto → Tokenización (DistilBERT) → Inferencia → Normalización → Respuesta
↓ ↓ ↓
512 tokens máx CPU-bound POSITIVE → positive
(threadpool) NEGATIVE → negative
| Aspecto | Valor Real | Archivo Fuente |
|---|---|---|
| Modelo | distilbert-base-uncased-finetuned-sst-2-english | sentiment_service.py |
| Pipeline | sentiment-analysis de HuggingFace | sentiment_service.py |
| Truncamiento | 512 tokens (automático) | sentiment_service.py línea 47 |
| Labels originales | POSITIVE, NEGATIVE → normalizados a minúsculas | sentiment_service.py líneas 64-67 |
| Clases de salida | SOLO BINARIO - positive o negative (sin neutral) | Arquitectura del modelo |
| Ejecución | run_in_threadpool (no bloquea async) | sentiment_service.py línea 51 |
Este modelo es binario (positive/negative únicamente). Fue entrenado con el dataset SST-2 (Stanford Sentiment Treebank) que solo contiene reseñas de películas positivas y negativas. El modelo NO tiene clase "neutral".
Comportamiento observado con texto neutral:
{"sentiment": "positive", "score": 0.9965}Esta es una característica conocida de las redes neuronales llamada "sobreconfianza" (ver: On Calibration of Modern Neural Networks, ICML 2017).
El modelo distilbert-base-uncased-finetuned-sst-2-english está entrenado para textos en inglés y ofrece rendimiento óptimo en este idioma.
Limitaciones conocidas:
positive o negative - NO existe clase neutralMejores casos de uso:
No recomendado para:
El modelo BERT tiene un límite de 512 tokens (~400 palabras). Si tu texto es más largo:
warning en la respuesta indicando el truncamientoRecomendación: Para textos largos, divídelos en párrafos y analiza cada uno por separado.
La primera petición tras inactividad puede tardar ~20 segundos (cold start). Una vez activo, las respuestas son < 500ms.
Nota de Transparencia: Esta API utiliza el modelo de código abierto
distilbert-base-uncased-finetuned-sst-2-englishde Hugging Face. Los resultados reflejan las capacidades y limitaciones inherentes del modelo, el cual fue entrenado exclusivamente con el dataset SST-2 (críticas de cine en inglés). ApisDom no modifica ni re-entrena el modelo base; proporcionamos una interfaz optimizada para su consumo vía API.Los scores de confianza (0.0-1.0) representan la certeza del modelo, no una medida absoluta de precisión. Para aplicaciones críticas, se recomienda validación humana adicional.
Última actualización de documentación: Enero 2026
ApisDom · Inteligencia Artificial Transparente
Esta API utiliza Chronos-2 (modelo pre-entrenado de Amazon Science para forecasting zero-shot) para generar predicciones precisas de series temporales con intervalos de confianza del 90%.
validate_periods para obtener MAPE real mediante backtesting.Viral
Plataforma pública de analítica predictiva construida sobre esta API.
Muestra resultados reales de forecasting, intervalos de confianza (lower/upper) y ausencia de maquillaje de métricas.
✅ Pronóstico de ventas e ingresos
✅ Predicción de tráfico web
✅ Gestión de inventario y planificación de demanda
✅ Planificación de recursos y capacidad
✅ Proyecciones de presupuesto
❌ Predicción de precios de bolsa o criptomonedas (muy volátiles)
❌ Extrapolación de un solo punto de datos
❌ Datos sin patrón temporal
| Propiedad | Valor |
|---|---|
| URL Base | https://apisdom.com/api/v1 |
| Método | POST |
| Autenticación | API Key (Header X-API-Key) |
| Tipo de Crédito | prediction |
| Coste por llamada | 1 crédito |
| Motor IA | Chronos-2 (Amazon Science zero-shot forecasting) |
| Límites de datos | Mínimo 10, máximo 5000 puntos de datos |
| Horizonte máximo | 365 períodos |
| Intervalos de confianza | 90% (quantiles 5% y 95%) |
La API devuelve headers que te permiten controlar tu consumo:
| Header | Descripción |
|---|---|
X-RateLimit-Limit | Tu límite de peticiones por minuto |
X-RateLimit-Remaining | Peticiones restantes en la ventana actual |
Retry-After | Segundos a esperar si recibes 429 |
Para optimizar costes, los microservicios de IA escalan a cero cuando no hay actividad.
💡 Nota: La primera petición puede tardar más de lo normal (hasta 20-30 segundos) mientras el servicio arranca. Las peticiones siguientes serán más rápidas (2-15 segundos dependiendo del tamaño de datos) mientras el servicio permanezca activo.
Consulta los planes disponibles y precios actualizados en: apisdom.com/pricing
Todas las peticiones requieren tu API Key en el header X-API-Key:
X-API-Key: tu_api_key_aqui
Puedes obtener tu API Key desde el panel de usuario en apisdom.com/dashboard.
Endpoint para verificar que el servicio está disponible. No requiere autenticación.
GET https://apisdom.com/api/health/predicciones
{
"status": "healthy",
"model": "chronos-2",
"service": "prediction"
}
POST https://apisdom.com/api/v1/predictions
| Campo | Tipo | Requerido | Default | Descripción |
|---|---|---|---|---|
dates | string[] | ✅ Si | - | Lista de fechas en formato YYYY-MM-DD. Minimo 10, maximo 5000. |
values | float[] | ✅ Si | - | Lista de valores numericos correspondientes. Debe tener la misma longitud que dates. |
periods | int | ❔ Opcional | 7 | Numero de periodos futuros a predecir. Minimo 1, maximo 365. |
validate_periods | int | ❔ Opcional | null | Periodos para backtesting MAPE (1-30). Si se proporciona, retorna MAPE real. |
is_open | bool[] | ❔ Opcional | null | Indica si el negocio estaba operativo cada dia. Debe tener la misma longitud que dates. Si se proporciona, los dias con false se tratan como datos ausentes. |
dates y values deben tener exactamente la misma longitudis_open, debe tener exactamente la misma longitud que datesEl campo is_open es opcional y permite distinguir entre dias sin actividad (negocio cerrado) y dias con ventas reales de cero.
Si NO envias is_open: Todo funciona como siempre. Los valores 0 se interpretan como datos reales. No necesitas cambiar nada en tu integracion actual.
Si envias is_open: Puedes indicar exactamente que dias el negocio estaba operativo.
is_open | value | Interpretacion | Tratamiento |
|---|---|---|---|
false | cualquier valor | Negocio cerrado | Ignorado (NaN) |
true | numero | Negocio abierto | Se usa el valor |
| no definido | numero | Comportamiento por defecto | Se usa el valor |
Recomendacion para mayor precision:
is_open: false cuando el negocio no podia vender (cerrado, festivo, inventario)value: 0 con is_open: true cuando el negocio estaba abierto pero no hubo ventasis_openEjemplo con is_open:
{
"dates": ["2026-04-07", "2026-04-08", "2026-04-09", "2026-04-10"],
"values": [5200, 0, 0, 4800],
"is_open": [true, false, true, true],
"periods": 7
}
En este ejemplo:
Error de validacion: Si is_open tiene longitud diferente a dates:
{
"detail": "is_open debe tener la misma longitud que dates. dates: 91, is_open: 10"
}
Codigo HTTP: 422 Unprocessable Entity
{
"dates": [
"2026-01-01", "2026-01-02", "2026-01-03", "2026-01-04", "2026-01-05",
"2026-01-06", "2026-01-07", "2026-01-08", "2026-01-09", "2026-01-10",
"2026-01-11", "2026-01-12", "2026-01-13", "2026-01-14", "2026-01-15"
],
"values": [
120.5, 135.2, 128.7, 142.1, 155.3,
148.9, 160.0, 172.4, 165.8, 180.2,
175.6, 188.9, 195.3, 201.7, 210.5
],
"periods": 7
}
La respuesta es ANIDADA con dos objetos principales: _metadata y response.
{
"_metadata": {
"provider": "ApisDom",
"tagline": "Inteligencia artificial transparente",
"website": "https://apisdom.com",
"timestamp": "2026-01-21T12:30:00.000Z",
"service": "Time Series Prediction",
"channel": "ApisDom Platform",
"request_id": "pred_1768954704623_abc123",
"documentation": "https://apisdom.com/documentacion"
},
"response": {
"predictions": [
{"date": "2026-01-16", "value": 218.34, "lower": 196.51, "upper": 240.17},
{"date": "2026-01-17", "value": 225.12, "lower": 202.61, "upper": 247.63},
{"date": "2026-01-18", "value": 231.89, "lower": 208.70, "upper": 255.08},
{"date": "2026-01-19", "value": 238.45, "lower": 214.61, "upper": 262.30},
{"date": "2026-01-20", "value": 245.01, "lower": 220.51, "upper": 269.51},
{"date": "2026-01-21", "value": 251.78, "lower": 226.60, "upper": 276.96},
{"date": "2026-01-22", "value": 258.34, "lower": 232.51, "upper": 284.17}
],
"mape": null,
"quality_warning": null,
"info_message": null
}
}
Nivel Raíz:
| Campo | Tipo | Descripción |
|---|---|---|
_metadata | object | Información del proveedor y tracking de la petición |
response | object | El resultado de la predicción |
Dentro de _metadata:
| Campo | Tipo | Descripción |
|---|---|---|
provider | string | Siempre "ApisDom" |
timestamp | string | Timestamp ISO 8601 de la petición |
request_id | string | Identificador único de esta petición |
service | string | Nombre del servicio ("Time Series Prediction") |
channel | string | Canal de distribución ("ApisDom Platform") |
Dentro de response:
| Campo | Tipo | Descripción |
|---|---|---|
predictions | array | Lista de predicciones con fecha y valores |
predictions[].date | string | Fecha predicha en formato YYYY-MM-DD |
predictions[].value | float | Valor predicho (mediana, percentil 50%) |
predictions[].lower | float | Límite inferior del intervalo de confianza 90% (percentil 5%) |
predictions[].upper | float | Límite superior del intervalo de confianza 90% (percentil 95%) |
mape | float | null | Mean Absolute Percentage Error. Retorna valor REAL solo si se proporcionó validate_periods, de lo contrario null. |
quality_warning | string | null | Aviso si hay datos insuficientes para validación MAPE (requiere parámetro validate_periods) |
info_message | string | null | Para usuarios free tier: aviso de cold start. null para planes de pago. |
Sobre intervalos de confianza: Los campos
loweryupperrepresentan intervalos de confianza del 90% calculados mediante regresión cuantílica con Chronos-2 (percentiles 5% y 95%). Esto significa que hay un 90% de probabilidad de que el valor real caiga dentro del rango [lower,upper].
El MAPE (Mean Absolute Percentage Error) se devuelve como valor decimal (0.0 a 1.0):
| MAPE (valor) | Error (%) | Interpretación | Confiabilidad |
|---|---|---|---|
| < 0.05 | < 5% | Excelente | ⭐⭐⭐⭐⭐ Muy alta |
| 0.05-0.10 | 5-10% | Bueno | ⭐⭐⭐⭐ Alta |
| 0.10-0.20 | 10-20% | Aceptable | ⭐⭐⭐ Media |
| 0.20-0.40 | 20-40% | Regular | ⭐⭐ Baja |
| > 0.40 | > 40% | Deficiente | ⭐ Muy baja - Considera usar más datos |
⚠️ Importante: El MAPE solo se calcula cuando proporcionas
validate_periods. Sin él,mapeseránull. Para obtener MAPE real, usa backtesting:
{
"dates": ["2026-01-01", "2026-01-02", ..., "2026-01-30"],
"values": [120.5, 135.2, ..., 210.5],
"periods": 7,
"validate_periods": 5
}
import requests
from typing import List
API_URL = "https://apisdom.com/api/v1/predictions"
API_KEY = "tu_api_key_aqui"
def predecir(fechas: List[str], valores: List[float], periodos: int = 7) -> dict:
"""
Genera predicciones para una serie temporal.
Args:
fechas: Lista de fechas en formato 'YYYY-MM-DD'
valores: Lista de valores numéricos
periodos: Número de periodos futuros a predecir (1-365)
Returns:
dict con _metadata y response conteniendo predictions y mape
"""
if len(fechas) != len(valores):
raise ValueError("fechas y valores deben tener la misma longitud")
if len(fechas) < 10:
raise ValueError("Se necesitan al menos 10 puntos de datos")
if not 1 <= periodos <= 365:
raise ValueError("periodos debe estar entre 1 y 365")
response = requests.post(
API_URL,
headers={
"X-API-Key": API_KEY,
"Content-Type": "application/json"
},
json={
"dates": fechas,
"values": valores,
"periods": periodos
}
)
if response.status_code == 200:
return response.json()
elif response.status_code == 402:
raise Exception("Sin créditos. Consulta planes en apisdom.com/pricing")
else:
raise Exception(f"Error: {response.status_code} - {response.text}")
# Ejemplo de uso
fechas = [
"2026-01-01", "2026-01-02", "2026-01-03", "2026-01-04", "2026-01-05",
"2026-01-06", "2026-01-07", "2026-01-08", "2026-01-09", "2026-01-10",
"2026-01-11", "2026-01-12", "2026-01-13", "2026-01-14", "2026-01-15"
]
valores = [120.5, 135.2, 128.7, 142.1, 155.3, 148.9, 160.0, 172.4, 165.8, 180.2, 175.6, 188.9, 195.3, 201.7, 210.5]
resultado = predecir(fechas, valores, periodos=7)
# IMPORTANTE: Acceder a los datos dentro del objeto 'response'
datos = resultado['response']
if datos['mape'] is not None:
print(f"MAPE: {datos['mape']:.1%}")
else:
print("MAPE: No calculado (usa validate_periods para obtener MAPE real)")
print(f"Request ID: {resultado['_metadata']['request_id']}")
print("\nPredicciones:")
for pred in datos['predictions']:
print(f" {pred['date']}: {pred['value']:.2f} [{pred['lower']:.2f} - {pred['upper']:.2f}]")
# Output (sin validate_periods):
# MAPE: No calculado (usa validate_periods para obtener MAPE real)
# Request ID: pred_1768954704623_abc123
#
# Predicciones:
# 2026-01-16: 218.34 [196.51 - 240.17]
# 2026-01-17: 225.12 [202.61 - 247.63]
# ...
const API_URL = 'https://apisdom.com/api/v1/predictions';
const API_KEY = 'tu_api_key_aqui';
async function predecir(fechas, valores, periodos = 7) {
/**
* Genera predicciones para una serie temporal.
* @param {string[]} fechas - Lista de fechas 'YYYY-MM-DD'
* @param {number[]} valores - Lista de valores numéricos
* @param {number} periodos - Periodos a predecir (1-365)
* @returns {Promise<Object>} - Resultado con _metadata y response
*/
if (fechas.length !== valores.length) {
throw new Error('fechas y valores deben tener la misma longitud');
}
if (fechas.length < 10) {
throw new Error('Se necesitan al menos 10 puntos de datos');
}
if (periodos < 1 || periodos > 365) {
throw new Error('periodos debe estar entre 1 y 365');
}
const response = await fetch(API_URL, {
method: 'POST',
headers: {
'X-API-Key': API_KEY,
'Content-Type': 'application/json'
},
body: JSON.stringify({ dates: fechas, values: valores, periods: periodos })
});
if (response.status === 402) {
throw new Error('Sin créditos. Consulta planes en apisdom.com/pricing');
}
if (!response.ok) {
throw new Error(`Error: ${response.status}`);
}
return response.json();
}
// Ejemplo de uso
const fechas = [
'2026-01-01', '2026-01-02', '2026-01-03', '2026-01-04', '2026-01-05',
'2026-01-06', '2026-01-07', '2026-01-08', '2026-01-09', '2026-01-10',
'2026-01-11', '2026-01-12', '2026-01-13', '2026-01-14', '2026-01-15'
];
const valores = [120.5, 135.2, 128.7, 142.1, 155.3, 148.9, 160.0, 172.4, 165.8, 180.2, 175.6, 188.9, 195.3, 201.7, 210.5];
predecir(fechas, valores, 7)
.then(resultado => {
// IMPORTANTE: Acceder al objeto 'response' anidado
const datos = resultado.response;
if (datos.mape !== null) {
console.log(`MAPE: ${(datos.mape * 100).toFixed(1)}%`);
} else {
console.log('MAPE: No calculado (usa validate_periods para obtener MAPE real)');
}
console.log(`Request ID: ${resultado._metadata.request_id}`);
console.log('\nPredicciones:');
datos.predictions.forEach(p => {
console.log(` ${p.date}: ${p.value.toFixed(2)} [${p.lower.toFixed(2)} - ${p.upper.toFixed(2)}]`);
});
})
.catch(console.error);
curl -X POST "https://apisdom.com/api/v1/predictions" \
-H "X-API-Key: tu_api_key_aqui" \
-H "Content-Type: application/json" \
-d '{
"dates": [
"2026-01-01", "2026-01-02", "2026-01-03", "2026-01-04", "2026-01-05",
"2026-01-06", "2026-01-07", "2026-01-08", "2026-01-09", "2026-01-10",
"2026-01-11", "2026-01-12", "2026-01-13", "2026-01-14", "2026-01-15"
],
"values": [120.5, 135.2, 128.7, 142.1, 155.3, 148.9, 160.0, 172.4, 165.8, 180.2, 175.6, 188.9, 195.3, 201.7, 210.5],
"periods": 7
}'
# La respuesta incluye _metadata y response anidados:
# {
# "_metadata": { "provider": "ApisDom", "request_id": "...", ... },
# "response": { "predictions": [...], "mape": null, ... }
# }
<?php
$api_url = 'https://apisdom.com/api/v1/predictions';
$api_key = 'tu_api_key_aqui';
function predecir($fechas, $valores, $periodos = 7) {
global $api_url, $api_key;
// Validaciones
if (count($fechas) !== count($valores)) {
throw new Exception('fechas y valores deben tener la misma longitud');
}
if (count($fechas) < 10) {
throw new Exception('Se necesitan al menos 10 puntos de datos');
}
if ($periodos < 1 || $periodos > 365) {
throw new Exception('periodos debe estar entre 1 y 365');
}
$ch = curl_init($api_url);
curl_setopt_array($ch, [
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POST => true,
CURLOPT_HTTPHEADER => [
'X-API-Key: ' . $api_key,
'Content-Type: application/json'
],
CURLOPT_POSTFIELDS => json_encode([
'dates' => $fechas,
'values' => $valores,
'periods' => $periodos
])
]);
$response = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
if ($httpCode === 402) {
throw new Exception('Sin créditos. Consulta planes en apisdom.com/pricing');
}
return json_decode($response, true);
}
// Ejemplo de uso
$fechas = [
'2026-01-01', '2026-01-02', '2026-01-03', '2026-01-04', '2026-01-05',
'2026-01-06', '2026-01-07', '2026-01-08', '2026-01-09', '2026-01-10',
'2026-01-11', '2026-01-12', '2026-01-13', '2026-01-14', '2026-01-15'
];
$valores = [120.5, 135.2, 128.7, 142.1, 155.3, 148.9, 160.0, 172.4, 165.8, 180.2, 175.6, 188.9, 195.3, 201.7, 210.5];
try {
$resultado = predecir($fechas, $valores, 7);
// IMPORTANTE: Acceder al objeto 'response' anidado
$datos = $resultado['response'];
if ($datos['mape'] !== null) {
echo "MAPE: " . number_format($datos['mape'] * 100, 1) . "%\n";
} else {
echo "MAPE: No calculado (usa validate_periods para obtener MAPE real)\n";
}
echo "Request ID: " . $resultado['_metadata']['request_id'] . "\n\n";
echo "Predicciones:\n";
foreach ($datos['predictions'] as $pred) {
echo " {$pred['date']}: " . number_format($pred['value'], 2) .
" [" . number_format($pred['lower'], 2) . " - " . number_format($pred['upper'], 2) . "]\n";
}
} catch (Exception $e) {
echo "Error: " . $e->getMessage() . "\n";
}
?>
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Text.Json.Serialization;
public class PredictionApiClient
{
private readonly HttpClient _client;
private const string API_URL = "https://apisdom.com/api/v1/predictions";
public PredictionApiClient(string apiKey)
{
_client = new HttpClient();
_client.DefaultRequestHeaders.Add("X-API-Key", apiKey);
}
public async Task<PredictionApiResponse> PredecirAsync(
List<string> fechas,
List<double> valores,
int periodos = 7)
{
// Validaciones
if (fechas.Count != valores.Count)
throw new ArgumentException("fechas y valores deben tener la misma longitud");
if (fechas.Count < 10)
throw new ArgumentException("Se necesitan al menos 10 puntos de datos");
if (periodos < 1 || periodos > 365)
throw new ArgumentException("periodos debe estar entre 1 y 365");
var request = new { dates = fechas, values = valores, periods = periodos };
var content = new StringContent(
JsonSerializer.Serialize(request),
Encoding.UTF8,
"application/json"
);
var response = await _client.PostAsync(API_URL, content);
if (response.StatusCode == System.Net.HttpStatusCode.PaymentRequired)
{
throw new Exception("Sin créditos. Consulta planes en apisdom.com/pricing");
}
response.EnsureSuccessStatusCode();
var json = await response.Content.ReadAsStringAsync();
return JsonSerializer.Deserialize<PredictionApiResponse>(json);
}
}
// IMPORTANTE: La respuesta es ANIDADA - necesitas estas clases
public class PredictionApiResponse
{
[JsonPropertyName("_metadata")]
public PredictionMetadata Metadata { get; set; }
[JsonPropertyName("response")]
public PredictionResult Response { get; set; }
}
public class PredictionMetadata
{
[JsonPropertyName("provider")]
public string Provider { get; set; }
[JsonPropertyName("request_id")]
public string RequestId { get; set; }
[JsonPropertyName("timestamp")]
public string Timestamp { get; set; }
}
public class PredictionResult
{
[JsonPropertyName("predictions")]
public List<Prediction> Predictions { get; set; }
[JsonPropertyName("mape")]
public double? Mape { get; set; } // Nullable - solo se establece si se proporcionó validate_periods
[JsonPropertyName("quality_warning")]
public string? QualityWarning { get; set; }
[JsonPropertyName("info_message")]
public string? InfoMessage { get; set; }
}
public class Prediction
{
[JsonPropertyName("date")]
public string Date { get; set; }
[JsonPropertyName("value")]
public double Value { get; set; }
[JsonPropertyName("lower")]
public double Lower { get; set; }
[JsonPropertyName("upper")]
public double Upper { get; set; }
}
// Ejemplo de uso
var client = new PredictionApiClient("tu_api_key_aqui");
var fechas = new List<string> {
"2026-01-01", "2026-01-02", "2026-01-03", "2026-01-04", "2026-01-05",
"2026-01-06", "2026-01-07", "2026-01-08", "2026-01-09", "2026-01-10",
"2026-01-11", "2026-01-12", "2026-01-13", "2026-01-14", "2026-01-15"
};
var valores = new List<double> { 120.5, 135.2, 128.7, 142.1, 155.3, 148.9, 160.0, 172.4, 165.8, 180.2, 175.6, 188.9, 195.3, 201.7, 210.5 };
var apiResponse = await client.PredecirAsync(fechas, valores, 7);
// Acceder a los datos dentro del objeto Response
if (apiResponse.Response.Mape.HasValue)
Console.WriteLine($"MAPE: {apiResponse.Response.Mape:P1}");
else
Console.WriteLine("MAPE: No calculado (usa validate_periods para obtener MAPE real)");
Console.WriteLine($"Request ID: {apiResponse.Metadata.RequestId}");
Console.WriteLine("\nPredicciones:");
foreach (var pred in apiResponse.Response.Predictions)
{
Console.WriteLine($" {pred.Date}: {pred.Value:N2} [{pred.Lower:N2} - {pred.Upper:N2}]");
}
def pronosticar_ventas(datos_historicos, dias_adelante=30):
"""
Genera pronóstico de ventas con análisis de tendencia.
"""
api_result = predecir(
datos_historicos['fechas'],
datos_historicos['valores'],
dias_adelante
)
# Acceder al objeto 'response' anidado
datos = api_result['response']
# Calcular métricas
valores_historicos = datos_historicos['valores']
valores_predichos = [p['value'] for p in datos['predictions']]
promedio_historico = sum(valores_historicos) / len(valores_historicos)
promedio_predicho = sum(valores_predichos) / len(valores_predichos)
cambio_porcentaje = ((promedio_predicho - promedio_historico) / promedio_historico) * 100
# Detectar tendencia
if cambio_porcentaje > 10:
tendencia = "📈 CRECIMIENTO FUERTE"
elif cambio_porcentaje > 3:
tendencia = "📈 Crecimiento moderado"
elif cambio_porcentaje > -3:
tendencia = "➡️ Estable"
elif cambio_porcentaje > -10:
tendencia = "📉 Declive moderado"
else:
tendencia = "📉 DECLIVE FUERTE"
return {
'predicciones': datos['predictions'],
'mape': datos['mape'],
'analisis': {
'tendencia': tendencia,
'cambio_porcentaje': f"{cambio_porcentaje:+.1f}%",
'total_proyectado': sum(valores_predichos)
}
}
async function predecirInventario(productId, stockActual, historialVentas) {
/**
* Predice cuándo se agotará el inventario y recomienda reposición.
*/
const apiResult = await predecir(
historialVentas.fechas,
historialVentas.valores,
30 // Predecir 30 días
);
// Acceder al objeto 'response' anidado
const datos = apiResult.response;
// Simular consumo de inventario
let stockRestante = stockActual;
let diasHastaAgotarse = null;
for (let i = 0; i < datos.predictions.length; i++) {
const pred = datos.predictions[i];
stockRestante -= pred.value;
if (stockRestante <= 0 && diasHastaAgotarse === null) {
diasHastaAgotarse = i + 1;
}
}
// Calcular nivel de alerta
let alerta;
if (diasHastaAgotarse !== null && diasHastaAgotarse <= 7) {
alerta = { nivel: 'CRITICO', emoji: '🔴', mensaje: '¡Reponer inmediatamente!' };
} else if (diasHastaAgotarse !== null && diasHastaAgotarse <= 14) {
alerta = { nivel: 'ALTO', emoji: '🟠', mensaje: 'Planificar reposición esta semana' };
} else if (diasHastaAgotarse !== null && diasHastaAgotarse <= 21) {
alerta = { nivel: 'MEDIO', emoji: '🟡', mensaje: 'Considerar reposición pronto' };
} else {
alerta = { nivel: 'BAJO', emoji: '🟢', mensaje: 'Nivel de stock saludable' };
}
return { productId, stockActual, diasHastaAgotarse, alerta };
}
def crear_dashboard_metricas(metricas_historicas, nombres_metricas):
"""
Crea un dashboard con múltiples métricas y sus proyecciones.
"""
resultados = []
for nombre, datos in zip(nombres_metricas, metricas_historicas.values()):
try:
api_result = predecir(datos['fechas'], datos['valores'], 7)
pred_data = api_result['response'] # Acceder al response anidado
historico = datos['valores']
proyectado = [p['value'] for p in pred_data['predictions']]
resultados.append({
'Métrica': nombre,
'Promedio Histórico': f"{sum(historico)/len(historico):,.1f}",
'Proyección 7 días': f"{sum(proyectado)/7:,.1f}",
'MAPE': f"{pred_data['mape']:.3f}" if pred_data['mape'] is not None else "N/A",
'Estado': '⚠️' if pred_data.get('quality_warning') else '✅'
})
except Exception as e:
resultados.append({'Métrica': nombre, 'Error': str(e)})
return resultados
| Código | Significado | Solución |
|---|---|---|
422 | Datos invalidos | Verifica: minimo 10 puntos, fechas=valores longitud, periodos 1-365, formato fecha YYYY-MM-DD, is_open misma longitud que dates |
401 | API Key inválida | Verifica tu API Key en el dashboard |
402 | Sin créditos disponibles | Consulta planes en apisdom.com/pricing |
429 | Límite de peticiones excedido | Espera antes de reintentar (ver header Retry-After) |
500 | Error interno del servidor | Reintenta en unos segundos. Si persiste, contacta soporte |
Política de ApisDom: Creemos que los desarrolladores merecen saber exactamente cómo funcionan las APIs que usan. Esta sección documenta los detalles técnicos verificados directamente del código fuente.
Tus datos → is_open? → DataFrame + covariables → Inferencia Chronos-2 → Prediccion → MAPE
↓ ↓ ↓ ↓ ↓
Si is_open pandas DataFrame modelo pre-entrenado predict_df backtesting
false→NaN + day_of_week (no entrena) con validacion
+ is_weekend covariables
| Aspecto | Valor Real | Archivo Fuente |
|---|---|---|
| Motor | Chronos-2 (Amazon Science) | prediction_service.py |
| Tipo | Zero-shot (pre-entrenado, no entrena por petición) | prediction_service.py |
| Modelo | amazon/chronos-2 (120M params) | prediction_service.py |
| Librería | chronos-forecasting==2.2.2 | requirements.txt |
| Método de inferencia | predict_df (con covariables nativas) | prediction_service.py |
| Covariables | day_of_week (0-6), is_weekend (0/1) — known future covariates | prediction_service.py |
| Intervalos de confianza | quantile_levels=[0.05, 0.5, 0.95] (90% confianza) | prediction_service.py |
| Postprocesamiento | Valores negativos clamped a 0 (revenue no puede ser negativo) | prediction_service.py |
| Dispositivo | CPU (CUDA si disponible) | prediction_service.py |
| Cálculo MAPE | Backtesting real (via validate_periods) | prediction_service.py |
# Código real (prediction_service.py) - Verificado 27 marzo 2026
def _calculate_mape(self, actual: list[float], predicted: list[float]) -> float | None:
"""
MAPE = (1/n) × Σ |actual - predicted| / |actual|
"""
if len(actual) != len(predicted):
return None
# Filtrar valores donde actual != 0 (evitar división por cero)
valid_pairs = [(a, p) for a, p in zip(actual, predicted, strict=True) if a != 0]
if not valid_pairs:
return None
errors = [abs(a - p) / abs(a) for a, p in valid_pairs]
return round(sum(errors) / len(errors), 4)
Importante: El MAPE se calcula via backtesting cuando se proporciona validate_periods. La API reserva los últimos N valores como ground truth, predice usando el resto, y compara.
Implicacion: Los valores 0 en el periodo de validacion se excluyen del calculo MAPE (para evitar division por cero). Si TODOS los valores de validacion son 0, el MAPE sera null. Si solo algunos son 0, el MAPE se calcula con los restantes. Si usas is_open: false para dias cerrados, esos dias tambien se excluyen del MAPE.
lower y upper Pueden Ser Diferentes a valueLos intervalos de confianza están implementados mediante regresión cuantílica:
# Código real (prediction_service.py) - Verificado 27 marzo 2026
pred_df = pipeline.predict_df(
context_df, # DataFrame histórico con covariables
future_df=future_df, # DataFrame futuro con covariables
prediction_length=periods,
quantile_levels=[0.05, 0.5, 0.95], # Genera percentiles 5%, 50% y 95%
id_column="item_id",
timestamp_column="timestamp",
target="target",
)
# Extrae valores del DataFrame de salida:
value = max(0.0, row["predictions"]) # Mediana (clamped >= 0)
lower = max(0.0, row["0.05"]) # Percentil 5% (clamped >= 0)
upper = max(0.0, row["0.95"]) # Percentil 95% (clamped >= 0)
Interpretación de tu resultado:
{
"date": "2026-01-18",
"value": 322.15, // Valor más probable (mediana)
"lower": 275.44, // 5% prob. de estar por debajo
"upper": 450.71 // 5% prob. de estar por encima
}
Esto significa: Hay 90% de confianza de que el valor real estará entre 275.44 y 450.71.
Nota: Los valores negativos se clampean a 0 automáticamente (revenue no puede ser negativo).
El MAPE (Mean Absolute Percentage Error) se devuelve como decimal (0.0 a 1.0):
mape: 0.05 = 5% de error (excelente)mape: 0.15 = 15% de error (aceptable)mape: 0.40 = 40% de error (considera usar más datos)mape: null = No se solicitó validación (usa validate_periods para obtener MAPE real)Para obtener MAPE REAL: Incluye validate_periods en tu petición (1-30). Esto realiza backtesting reservando los últimos N valores como ground truth.
Para convertir a porcentaje: mape * 100
| Factor | Impacto | Recomendación |
|---|---|---|
| Cantidad de datos | Alto | Mínimo 30 puntos para predicciones confiables |
| Regularidad temporal | Alto | Usa frecuencia consistente (diaria, semanal) |
| Valores atípicos | Medio | Limpia outliers antes de enviar |
| Estacionalidad | Medio | Incluye al menos 1 ciclo completo |
| Tendencia clara | Alto | Series con tendencia tienen mejor MAPE |
quality_warning ApareceRecibirás quality_warning cuando:
validate_periods está especificado pero hay datos insuficientes para backtestingvalidate_periods + 10 puntos (10 para training, resto para validación)validate_periods: 7, necesitas al menos 17 puntos de datosImportante: Sin validate_periods, no se genera ningún quality_warning (y mape es null).
| Puntos de Datos | Tiempo Estimado |
|---|---|
| 10-100 | < 2 segundos |
| 100-1000 | 2-5 segundos |
| 1000-5000 | 5-15 segundos |
Nota: La primera petición del día puede tener ~20-30s de latencia adicional (cold start).
Nota de Transparencia: Esta API utiliza el modelo de código abierto Chronos-2 de Amazon Science para pronósticos de series temporales. Los resultados reflejan las capacidades y limitaciones inherentes del modelo. ApisDom proporciona una interfaz optimizada para consumo vía API.
Las predicciones son estimaciones estadísticas basadas en patrones históricos. No deben usarse como única base para decisiones de negocio críticas. Para aplicaciones de alto riesgo, se recomienda validación adicional.
Los intervalos de confianza (lower/upper) representan límites de probabilidad del 90%, no garantías. Los valores reales pueden caer fuera de estos rangos el 10% de las veces.
Ultima actualizacion de documentacion: 10 de abril de 2026
*ApisDom · Inteligencia Artificial Transparente
Esta API utiliza el modelo Toxic-BERT (fine-tuned en el dataset Jigsaw Toxic Comment Classification Challenge) para detectar contenido tóxico, discurso de odio, insultos, amenazas y lenguaje obsceno en texto en inglés.
toxic, severe_toxic, obscene, threat, insult, identity_hate. Todas las categorías se devuelven independientemente del score.is_toxic se activa cuando toxicity_score > 0.7 (puedes implementar tu propio umbral en código).LITERAL de la documentación oficial de Hugging Face:
"If words that are associated with swearing, insults or profanity are present in a comment, it is likely that it will be classified as toxic, regardless of the tone or the intent of the author e.g. humorous/self-deprecating. This could present some biases towards already vulnerable minority groups."
Traducción: Si hay palabras asociadas a insultos o blasfemias, el modelo las clasificará como tóxicas sin importar el tono o la intención del autor (humor, autodesprecio, citas, etc.).
| Escenario | Comportamiento | Ejemplo |
|---|---|---|
| Insulto con palabrotas | ✅ Detecta correctamente | "Eres un idiota" → toxic |
| Humor con palabrotas | ⚠️ Marca como tóxico (falso positivo) | "Soy un idiota jajaja" → toxic |
| Auto-desprecio humorístico | ⚠️ Marca como tóxico | "Me odio a mí mismo lol" → toxic |
| Cita de contenido tóxico | ⚠️ Marca como tóxico | "Él dijo 'eres idiota'" → toxic |
| Sarcasmo sin palabrotas | ❌ NO detecta | "Qué inteligente eres..." → not toxic |
| Pasivo-agresivo | ❌ NO detecta | "Bonito trabajo, lástima que no sirva" → not toxic |
Importante: El modelo detecta vocabulario, NO intención. El sarcasmo, la ironía y el pasivo-agresivo NO son detectados.
✅ Moderación de comentarios (foros, blogs, redes sociales)
✅ Filtrado de chat (gaming, comunidades)
✅ Screening de contenido generado por usuarios
✅ Triaje de tickets de soporte (detectar clientes enfadados)
❌ Detectar sarcasmo o negatividad sutil
❌ Contenido en idiomas distintos al inglés
❌ Moderación dependiente del contexto (puede requerir revisión humana)
| Propiedad | Valor |
|---|---|
| URL Base | https://apisdom.com/api/v1 |
| Método | POST |
| Autenticación | API Key (Header X-API-Key) |
| Tipo de Crédito | text |
| Coste por llamada | 1 crédito |
| Modelo IA | Toxic-BERT (unitary/toxic-bert de HuggingFace) |
| Límite de tokens | 512 tokens (textos largos serán truncados) |
| Datos de entrenamiento | Jigsaw Toxic Comment Classification Challenge (comentarios de Wikipedia) |
| Categorías de salida | 6 fijas: toxic, severe_toxic, obscene, threat, insult, identity_hate |
| Métrica | Leaderboard | Test Set |
|---|---|---|
| ROC-AUC | 0.98856 | 0.98636 |
Fuente: Jigsaw Toxic Comment Classification Challenge (2018)
| Escenario | Tiempo de Respuesta |
|---|---|
| En caliente (servicio activo) | 30-80 ms |
| Cold start (primera petición) | ~20 segundos |
Experiencia de usuario en tiempo real: En chats de gaming, foros o redes sociales, los usuarios esperan que sus mensajes aparezcan instantáneamente. Una latencia de 30-80ms es imperceptible para el usuario, permitiendo moderar sin que nadie note el filtro.
Escalabilidad masiva: Con ~35ms por inferencia, puedes procesar ~28 mensajes por segundo por instancia. Para plataformas con millones de usuarios activos, esto marca la diferencia entre un sistema que escala y uno que colapsa.
Prevención proactiva: Cuanto antes detectes contenido tóxico, menos usuarios lo verán. En comunidades virales, un mensaje ofensivo puede ser visto por miles de personas en segundos. La moderación en <100ms permite bloquear ANTES de que se propague.
Ahorro en moderación humana: Con pre-filtrado rápido, los moderadores humanos solo revisan el ~5-10% del contenido (zona amarilla del semáforo), no el 100%. Esto reduce costes de personal y burnout.
Cumplimiento legal: Regulaciones como la DSA (Digital Services Act) de la UE exigen "actuación rápida" contra contenido ilegal. Una API lenta puede significar incumplimiento normativo.
Nota técnica: La latencia de 30-80ms se logra con el modelo en memoria (GPU/CPU). El cold start de ~20s ocurre solo tras períodos de inactividad (escalado a cero para optimizar costes).
La API devuelve headers que te permiten controlar tu consumo:
| Header | Descripción |
|---|---|
X-RateLimit-Limit | Tu límite de peticiones por minuto |
X-RateLimit-Remaining | Peticiones restantes en la ventana actual |
Retry-After | Segundos a esperar si recibes 429 |
Para optimizar costes, los microservicios de IA escalan a cero cuando no hay actividad.
💡 Nota: La primera petición puede tardar más de lo normal mientras el servicio arranca. Las peticiones siguientes serán mucho más rápidas mientras el servicio permanezca activo.
Consulta los planes disponibles y precios actualizados en: apisdom.com/pricing
Todas las peticiones requieren tu API Key en el header X-API-Key:
X-API-Key: tu_api_key_aqui
Puedes obtener tu API Key desde el panel de usuario en apisdom.com/dashboard.
Endpoint para verificar que el servicio está disponible. No requiere autenticación.
GET https://apisdom.com/api/v1/moderacion
{
"status": "healthy",
"service": "moderation",
"valid": true,
"timestamp": "2026-01-21T03:45:00.000Z",
"provider": "ApisDom"
}
POST https://apisdom.com/api/v1/moderacion
| Campo | Tipo | Requerido | Descripción |
|---|---|---|---|
text | string | ✅ Sí | Texto a moderar. Mínimo 1 carácter, máximo 5000. |
{
"text": "You are an idiot and should disappear."
}
La respuesta es ANIDADA con dos objetos principales: _metadata y response.
{
"_metadata": {
"provider": "ApisDom",
"tagline": "Inteligencia artificial transparente",
"website": "https://apisdom.com",
"timestamp": "2026-01-21T03:45:00.000Z",
"service": "Content Moderation",
"channel": "ApisDom Platform",
"request_id": "mod_1768965900123_abc123",
"documentation": "https://apisdom.com/documentacion"
},
"response": {
"text": "You are an idiot and should disappear.",
"is_toxic": true,
"toxicity_score": 0.923,
"categories": {
"toxic": 0.923,
"severe_toxic": 0.145,
"obscene": 0.321,
"threat": 0.087,
"insult": 0.876,
"identity_hate": 0.023
},
"warning": null,
"info_message": null
}
}
Nivel Raíz:
| Campo | Tipo | Descripción |
|---|---|---|
_metadata | object | Información del proveedor y tracking de la petición |
response | object | El resultado del análisis de moderación |
Dentro de _metadata:
| Campo | Tipo | Descripción |
|---|---|---|
provider | string | Siempre "ApisDom" |
timestamp | string | Timestamp ISO 8601 de la petición |
request_id | string | Identificador único de esta petición |
service | string | Nombre del servicio ("Content Moderation") |
channel | string | Canal de distribución ("ApisDom Platform") |
Dentro de response:
| Campo | Tipo | Descripción |
|---|---|---|
text | string | El texto que fue analizado |
is_toxic | boolean | true si toxicity_score > 0.7, false en caso contrario |
toxicity_score | float | Puntuación máxima de toxicidad detectada (0.0 a 1.0) |
categories | object | Todas las 6 categorías estándar con sus scores (0.0-1.0) |
warning | string | null | Aviso si el texto fue truncado (textos muy largos) |
info_message | string | null | Información adicional sobre el análisis |
| Categoría | Descripción |
|---|---|
toxic | Toxicidad general (categoría principal) |
severe_toxic | Toxicidad extrema/severa |
obscene | Lenguaje vulgar u obsceno |
threat | Amenazas o intimidación |
insult | Insultos directos |
identity_hate | Discurso de odio basado en identidad (raza, religión, orientación, etc.) |
⚠️ Importante: El objeto
categoriesSIEMPRE incluye las 6 categorías con sus scores, incluso si son bajos (ej:threat: 0.05significa 5% de probabilidad). Filtra por umbral en tu código si solo quieres mostrar categorías relevantes (ej:score > 0.5).
import requests
API_URL = "https://apisdom.com/api/v1/moderacion"
API_KEY = "tu_api_key_aqui"
def moderar_contenido(texto):
"""
Analiza un texto para detectar contenido tóxico.
Args:
texto: String con el texto a moderar (máx 5000 caracteres)
Returns:
dict con _metadata y response conteniendo is_toxic, toxicity_score y categories
"""
response = requests.post(
API_URL,
headers={
"X-API-Key": API_KEY,
"Content-Type": "application/json"
},
json={"text": texto}
)
if response.status_code == 200:
return response.json()
elif response.status_code == 402:
raise Exception("Sin créditos. Consulta planes en apisdom.com/pricing")
else:
raise Exception(f"Error: {response.status_code} - {response.text}")
def debe_bloquear(resultado, umbral=0.7):
"""
Determina si un contenido debe ser bloqueado.
Args:
resultado: Respuesta de moderar_contenido()
umbral: Puntuación mínima para bloquear (default 0.7)
Returns:
True si debe bloquearse, False si puede publicarse
"""
# IMPORTANTE: Acceder al objeto 'response' anidado
datos = resultado['response']
# Bloquear si toxicidad general supera umbral
if datos['toxicity_score'] >= umbral:
return True
# Tolerancia cero para amenazas y ataques de identidad
categorias = datos['categories']
if categorias.get('threat', 0) >= 0.5:
return True
if categorias.get('identity_hate', 0) >= 0.5:
return True
return False
# Ejemplo de uso
resultado = moderar_contenido("Thank you for your help, you are great!")
# IMPORTANTE: Acceder a los datos dentro del objeto 'response'
datos = resultado['response']
print(f"Es tóxico: {datos['is_toxic']}")
print(f"Score toxicidad: {datos['toxicity_score']:.2%}")
print(f"Request ID: {resultado['_metadata']['request_id']}")
if debe_bloquear(resultado):
print("❌ BLOQUEADO - Contenido inapropiado")
else:
print("✅ APROBADO - Contenido apropiado")
# Output:
# Es tóxico: False
# Score toxicidad: 2.00%
# Request ID: mod_1768965900123_abc123
# ✅ APROBADO - Contenido apropiado
const API_URL = 'https://apisdom.com/api/v1/moderacion';
const API_KEY = 'tu_api_key_aqui';
async function moderarContenido(texto) {
/**
* Analiza un texto para detectar contenido tóxico.
* @param {string} texto - Texto a moderar (máx 5000 caracteres)
* @returns {Promise<Object>} - Resultado con _metadata y response
*/
const response = await fetch(API_URL, {
method: 'POST',
headers: {
'X-API-Key': API_KEY,
'Content-Type': 'application/json'
},
body: JSON.stringify({ text: texto })
});
if (response.status === 402) {
throw new Error('Sin créditos. Consulta planes en apisdom.com/pricing');
}
if (!response.ok) {
throw new Error(`Error: ${response.status}`);
}
return response.json();
}
function debeBloquear(resultado, umbral = 0.7) {
// IMPORTANTE: Acceder al objeto 'response' anidado
const datos = resultado.response;
if (datos.toxicity_score >= umbral) return true;
if (datos.categories.threat >= 0.5) return true;
if (datos.categories.identity_hate >= 0.5) return true;
return false;
}
// Ejemplo de uso
moderarContenido('You are an idiot and should disappear')
.then(resultado => {
// IMPORTANTE: Acceder al objeto 'response' anidado
const datos = resultado.response;
console.log(`Es tóxico: ${datos.is_toxic}`);
console.log(`Score toxicidad: ${(datos.toxicity_score * 100).toFixed(2)}%`);
console.log(`Request ID: ${resultado._metadata.request_id}`);
// Mostrar categorías detectadas
const categoriasAltas = Object.entries(datos.categories)
.filter(([_, score]) => score >= 0.5)
.sort((a, b) => b[1] - a[1])
.map(([cat, score]) => `${cat}: ${(score * 100).toFixed(0)}%`);
if (categoriasAltas.length > 0) {
console.log(`Detectado: ${categoriasAltas.join(', ')}`);
}
// Output:
// Es tóxico: true
// Score toxicidad: 92.30%
// Request ID: mod_1768965900456_def456
// Detectado: toxic: 92%, insult: 88%
})
.catch(console.error);
curl -X POST "https://apisdom.com/api/v1/moderacion" \
-H "X-API-Key: tu_api_key_aqui" \
-H "Content-Type: application/json" \
-d '{"text": "Thank you for your help, this tutorial is very useful!"}'
# La respuesta incluye _metadata y response anidados:
# {
# "_metadata": { "provider": "ApisDom", "request_id": "...", ... },
# "response": { "text": "...", "is_toxic": false, "toxicity_score": 0.02, "categories": {...} }
# }
<?php
$api_url = 'https://apisdom.com/api/v1/moderacion';
$api_key = 'tu_api_key_aqui';
function moderarContenido($texto) {
global $api_url, $api_key;
$ch = curl_init($api_url);
curl_setopt_array($ch, [
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POST => true,
CURLOPT_HTTPHEADER => [
'X-API-Key: ' . $api_key,
'Content-Type: application/json'
],
CURLOPT_POSTFIELDS => json_encode(['text' => $texto])
]);
$response = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
if ($httpCode === 402) {
throw new Exception('Sin créditos. Consulta planes en apisdom.com/pricing');
}
return json_decode($response, true);
}
function debeBloquear($resultado, $umbral = 0.7) {
// IMPORTANTE: Acceder al objeto 'response' anidado
$datos = $resultado['response'];
if ($datos['toxicity_score'] >= $umbral) return true;
if ($datos['categories']['threat'] >= 0.5) return true;
if ($datos['categories']['identity_hate'] >= 0.5) return true;
return false;
}
// Ejemplo de uso
$resultado = moderarContenido('Great article, very well explained!');
// IMPORTANTE: Acceder al objeto 'response' anidado
$datos = $resultado['response'];
echo "Es tóxico: " . ($datos['is_toxic'] ? 'Sí' : 'No') . "\n";
echo "Score toxicidad: " . number_format($datos['toxicity_score'] * 100, 2) . "%\n";
echo "Request ID: " . $resultado['_metadata']['request_id'] . "\n";
if (debeBloquear($resultado)) {
echo "❌ BLOQUEADO - Contenido inapropiado\n";
} else {
echo "✅ APROBADO - Contenido apropiado\n";
}
// Output:
// Es tóxico: No
// Score toxicidad: 1.50%
// Request ID: mod_1768965900789_ghi789
// ✅ APROBADO - Contenido apropiado
?>
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Text.Json.Serialization;
public class ModerationApiClient
{
private readonly HttpClient _client;
private const string API_URL = "https://apisdom.com/api/v1/moderacion";
public ModerationApiClient(string apiKey)
{
_client = new HttpClient();
_client.DefaultRequestHeaders.Add("X-API-Key", apiKey);
}
public async Task<ModerationApiResponse> ModerarContenidoAsync(string texto)
{
var content = new StringContent(
JsonSerializer.Serialize(new { text = texto }),
Encoding.UTF8,
"application/json"
);
var response = await _client.PostAsync(API_URL, content);
if (response.StatusCode == System.Net.HttpStatusCode.PaymentRequired)
{
throw new Exception("Sin créditos. Consulta planes en apisdom.com/pricing");
}
response.EnsureSuccessStatusCode();
var json = await response.Content.ReadAsStringAsync();
return JsonSerializer.Deserialize<ModerationApiResponse>(json);
}
}
// IMPORTANTE: La respuesta es ANIDADA - necesitas estas clases
public class ModerationApiResponse
{
[JsonPropertyName("_metadata")]
public ModerationMetadata Metadata { get; set; }
[JsonPropertyName("response")]
public ModerationResult Response { get; set; }
}
public class ModerationMetadata
{
[JsonPropertyName("provider")]
public string Provider { get; set; }
[JsonPropertyName("request_id")]
public string RequestId { get; set; }
[JsonPropertyName("timestamp")]
public string Timestamp { get; set; }
}
public class ModerationResult
{
[JsonPropertyName("text")]
public string Text { get; set; }
[JsonPropertyName("is_toxic")]
public bool IsToxic { get; set; }
[JsonPropertyName("toxicity_score")]
public double ToxicityScore { get; set; }
[JsonPropertyName("categories")]
public ToxicityCategories Categories { get; set; }
[JsonPropertyName("warning")]
public string? Warning { get; set; }
[JsonPropertyName("info_message")]
public string? InfoMessage { get; set; }
}
public class ToxicityCategories
{
[JsonPropertyName("toxic")]
public double Toxic { get; set; }
[JsonPropertyName("severe_toxic")]
public double SevereToxic { get; set; }
[JsonPropertyName("obscene")]
public double Obscene { get; set; }
[JsonPropertyName("threat")]
public double Threat { get; set; }
[JsonPropertyName("insult")]
public double Insult { get; set; }
[JsonPropertyName("identity_hate")]
public double IdentityHate { get; set; }
}
// Ejemplo de uso
var client = new ModerationApiClient("tu_api_key_aqui");
var apiResponse = await client.ModerarContenidoAsync("You are amazing, thank you!");
// Acceder a los datos dentro del objeto Response
Console.WriteLine($"Es tóxico: {apiResponse.Response.IsToxic}");
Console.WriteLine($"Score toxicidad: {apiResponse.Response.ToxicityScore:P2}");
Console.WriteLine($"Request ID: {apiResponse.Metadata.RequestId}");
// Output:
// Es tóxico: False
// Score toxicidad: 1.20%
// Request ID: mod_1768965900999_jkl999
La documentación oficial del modelo cita estos papers sobre sesgos en detección de toxicidad:
Advertencia oficial: El modelo puede tener sesgos hacia grupos vulnerables minoritarios porque el contenido que menciona identidades (raza, religión, orientación sexual) puede ser clasificado como tóxico incluso cuando no lo es.
"The intended use of this library is for research purposes, fine-tuning on carefully constructed datasets that reflect real world demographics and/or to aid content moderators in flagging out harmful content quicker."
| Uso | Recomendación |
|---|---|
| ✅ Investigación | Sí - uso previsto |
| ✅ Pre-filtrado para moderadores humanos | Sí - uso previsto |
| ✅ Sanitización automática a escala | Sí - acelera detección |
| ⚠️ Decisiones automáticas de baneo | Con precaución - revisar falsos positivos |
| ❌ Juez único sin revisión humana | No recomendado |
| ❌ Detección de sarcasmo/ironía | No funciona |
| ❌ Análisis de intención | No funciona |
comentarios = [
"Great tutorial, very helpful!",
"You are an idiot, this is garbage",
"I disagree with this approach",
]
for comentario in comentarios:
api_result = moderar_contenido(comentario)
# Acceder al objeto 'response' anidado
datos = api_result['response']
estado = "❌ BLOQUEADO" if datos['is_toxic'] else "✅ APROBADO"
print(f"'{comentario[:30]}...' → {estado} ({datos['toxicity_score']:.0%})")
# Output:
# 'Great tutorial, very helpful!...' → ✅ APROBADO (2%)
# 'You are an idiot, this is gar...' → ❌ BLOQUEADO (94%)
# 'I disagree with this approach...' → ✅ APROBADO (5%)
def filtrar_mensaje_chat(mensaje, username):
"""Filtra mensajes de chat en tiempo real."""
api_result = moderar_contenido(mensaje)
# Acceder al objeto 'response' anidado
datos = api_result['response']
if datos['is_toxic']:
# Registrar el incidente
categorias = datos['categories']
detectadas = [cat for cat, score in categorias.items() if score >= 0.5]
print(f"⚠️ Mensaje bloqueado de {username}: {detectadas}")
return None # No mostrar el mensaje
return mensaje # Seguro para mostrar
# Ejemplo
msg = filtrar_mensaje_chat("You're the worst player ever, uninstall!", "toxic_user123")
# Output: ⚠️ Mensaje bloqueado de toxic_user123: ['toxic', 'insult']
async function moderarLote(contenidos) {
const apiResults = await Promise.all(
contenidos.map(c => moderarContenido(c.text))
);
// Extraer el objeto 'response' de cada resultado de la API
const resultados = apiResults.map(r => r.response);
const stats = {
total: resultados.length,
toxicos: resultados.filter(r => r.is_toxic).length,
limpios: resultados.filter(r => !r.is_toxic).length,
promedioToxicidad: resultados.reduce((a, b) => a + b.toxicity_score, 0) / resultados.length
};
console.log('📊 Resumen de Moderación:');
console.log(` Total: ${stats.total}`);
console.log(` ❌ Tóxicos: ${stats.toxicos}`);
console.log(` ✅ Limpios: ${stats.limpios}`);
console.log(` 📊 Toxicidad promedio: ${(stats.promedioToxicidad * 100).toFixed(1)}%`);
return stats;
}
Dado que el modelo no es un juez perfecto, se recomienda una lógica de tres niveles en lugar de una decisión binaria:
| Nivel | Score | Acción | Razón |
|---|---|---|---|
| 🟢 Verde | < 0.60 | Permitir automáticamente | Contenido seguro |
| 🟡 Amarillo | 0.60 - 0.90 | Marcar para revisión humana | Zona de riesgo (sarcasmo, falsos positivos) |
| 🔴 Rojo | > 0.90 | Bloqueo automático | Toxicidad explícita casi segura |
def procesar_comentario(texto_usuario):
# 1. Llamada a Apisdom
resultado = moderar_contenido(texto_usuario)
datos = resultado['response']
score = datos['toxicity_score']
# 2. Lógica de Semáforo (gestionando la incertidumbre)
# CASO A: Toxicidad extrema (Bloqueo inmediato)
if score >= 0.90:
return {
"accion": "BLOQUEAR",
"mensaje": "Tu comentario ha sido rechazado por violar las normas.",
"revision_requerida": False
}
# CASO B: Zona Gris (Revisión Humana)
# Aquí caen el sarcasmo, falsos positivos, discusiones acaloradas
elif score >= 0.60:
guardar_para_revision(texto_usuario, score)
return {
"accion": "FLAG",
"mensaje": "Tu comentario está pendiente de aprobación.",
"revision_requerida": True
}
# CASO C: Contenido Seguro (Publicación inmediata)
else:
return {
"accion": "PUBLICAR",
"mensaje": None,
"revision_requerida": False
}
Para plataformas donde los usuarios usan jerga agresiva no tóxica (gaming, foros especializados):
async function checkContent(user, text) {
const apiResponse = await moderarContenido(text);
const datos = apiResponse.response;
// Si el usuario es veterano/premium, somos más permisivos
const threshold = user.isTrusted ? 0.95 : 0.80;
if (datos.toxicity_score > threshold) {
// Doble chequeo: ¿Es solo "obsceno" pero no "amenaza" ni "odio"?
const cats = datos.categories;
if (cats.obscene > 0.9 && cats.identity_hate < 0.1 && cats.threat < 0.1) {
return "ALLOW_WITH_WARNING"; // Permitir palabrotas si no hay odio
}
return "BLOCK";
}
return "ALLOW";
}
En lugar de un error genérico, usa las categorías para educar al usuario:
def generar_mensaje_rechazo(datos):
categorias_detectadas = []
if datos['categories']['insult'] >= 0.7:
categorias_detectadas.append(f"• Insultos directos (Confianza: {datos['categories']['insult']:.0%})")
if datos['categories']['obscene'] >= 0.5:
categorias_detectadas.append(f"• Lenguaje obsceno (Confianza: {datos['categories']['obscene']:.0%})")
if datos['categories']['threat'] >= 0.5:
categorias_detectadas.append(f"• Amenazas (Confianza: {datos['categories']['threat']:.0%})")
if datos['categories']['identity_hate'] >= 0.5:
categorias_detectadas.append(f"• Discurso de odio (Confianza: {datos['categories']['identity_hate']:.0%})")
if categorias_detectadas:
return f"""No hemos podido publicar tu comentario. Nuestro sistema ha detectado:
{chr(10).join(categorias_detectadas)}
Por favor, reformula tu mensaje manteniendo el respeto.
💡 Nota: Si crees que es un error (sarcasmo, cita, etc.),
contacta con soporte indicando el ID de petición."""
return "Comentario rechazado por contenido inapropiado."
¿Por qué esto ayuda? Al exponer la categoría específica, el usuario entiende qué hizo mal. Si fue un falso positivo (sarcasmo), podrá reescribirlo de forma más clara, reduciendo frustración y quejas al soporte.
| Código | Significado | Solución |
|---|---|---|
400 | Texto inválido (vacío o muy largo) | Asegúrate de enviar entre 1 y 5000 caracteres |
401 | API Key inválida | Verifica tu API Key en el dashboard |
402 | Sin créditos disponibles | Consulta planes en apisdom.com/pricing |
429 | Límite de peticiones excedido | Espera antes de reintentar (ver headers de rate limit) |
500 | Error interno del servidor | Reintenta en unos segundos. Si persiste, contacta soporte |
Política de ApisDom: Creemos que los desarrolladores merecen saber exactamente cómo funcionan las APIs que usan. Esta sección documenta los detalles técnicos verificados directamente del código fuente.
Tu texto → Tokenización (BERT) → Inferencia → Clasificación Multi-label → Respuesta
↓ ↓ ↓
512 tokens máx CPU-bound 6 categorías con scores
(threadpool) + verificación umbral is_toxic
| Aspecto | Valor |
|---|---|
| Modelo | unitary/toxic-bert (HuggingFace) |
| Pipeline | text-classification de HuggingFace Transformers |
| Truncamiento | 512 tokens (automático) |
| Categorías de salida | 6 fijas: toxic, severe_toxic, obscene, threat, insult, identity_hate |
| Umbral is_toxic | max(toxicity_score) > 0.7 |
| Ejecución | Async no bloqueante (threadpool) |
El modelo Toxic-BERT es un clasificador multi-label. Fue entrenado con el dataset Jigsaw Toxic Comment Classification Challenge (comentarios de Wikipedia). El modelo SIEMPRE devuelve las 6 categorías con sus scores de confianza, incluso si son bajos.
Ejemplo con texto no tóxico:
is_toxic será false porque toxicity_score < 0.7El modelo unitary/toxic-bert está entrenado para textos en inglés y ofrece rendimiento óptimo en este idioma.
Limitaciones conocidas:
Mejores casos de uso:
No recomendado para:
| Tipo de Plataforma | Umbral Toxicidad | Umbral Amenazas | Umbral Identidad |
|---|---|---|---|
| Foro para niños | 0.3 | 0.2 | 0.2 |
| Red social general | 0.5 | 0.4 | 0.4 |
| Foro de adultos | 0.7 | 0.4 | 0.5 |
| Chat privado | 0.8 | 0.5 | 0.6 |
El modelo BERT tiene un límite de 512 tokens (~400 palabras). Si tu texto es más largo:
warning en la respuesta indicando el truncamientoRecomendación: Para textos largos, divídelos en párrafos y analiza cada uno por separado.
Ver sección ⚡ Velocidad y Latencia para detalles completos sobre latencias y por qué la velocidad es crítica en moderación de contenido.
Nota de Transparencia: Esta API utiliza el modelo de código abierto
unitary/toxic-bertde Hugging Face, desarrollado por Laura Hanu @ Unitary. Los resultados reflejan las capacidades y limitaciones inherentes del modelo, el cual fue entrenado exclusivamente con el dataset Jigsaw (comentarios de Wikipedia en inglés). ApisDom no modifica ni re-entrena el modelo base; proporcionamos una interfaz optimizada para su consumo vía API.Los scores de confianza (0.0-1.0) representan la certeza del modelo, no una medida absoluta de precisión. Para aplicaciones críticas, se recomienda validación humana adicional.
Pre-filtrado rápido de contenido a escala para asistir moderadores humanos, NO como juez único de decisiones automáticas de baneo sin revisión.
| Recurso | URL |
|---|---|
| Hugging Face Model | https://huggingface.co/unitary/toxic-bert |
| GitHub Repository | https://github.com/unitaryai/detoxify |
| Jigsaw Challenge | https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge |
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}
Última actualización de documentación: Enero 2026*
ApisDom · Inteligencia Artificial Transparente
Genera recomendaciones personalizadas basadas en similitud semántica utilizando sentence-transformers (all-MiniLM-L6-v2), identificando los contenidos más relevantes para una consulta específica.
sentence-transformers/all-MiniLM-L6-v2, optimizado para similitud semántica en inglés. Funciona con español pero con menor precisión.⚠️ REQUISITO DE INTEGRACIÓN: Esta sección es obligatoria para obtener resultados precisos en búsquedas complejas. El 90% de los problemas de "baja precisión" se resuelven aplicando estas técnicas.
El motor de recomendaciones funciona mediante similitud vectorial. Esto significa que calcula la distancia matemática entre el texto de la consulta (query) y el texto de los elementos (contents).
Limitación crítica: El motor NO realiza inferencias lógicas ni tiene conocimiento externo.
| Lo que el modelo PUEDE hacer | Lo que el modelo NO puede hacer |
|---|---|
| Comparar palabras y sus sinónimos aprendidos | "Saber" que Tesla es ecológico |
| Detectar similitud semántica entre frases | Inferir atributos no escritos |
| Ordenar por relevancia textual | Razonar sobre el mundo real |
Ejemplo real:
contents)No envíes solo el nombre del producto. Concatena las características clave, categorías y sinónimos dentro de la misma cadena de texto.
El modelo solo tiene el nombre para trabajar. Resultados pobres garantizados.
{
"query": "laptop económica para estudiante",
"contents": [
"HP 15",
"MacBook Pro",
"Dell Inspiron"
]
}
Resultado: Scores bajos (~0.30-0.45), el modelo no tiene contexto para decidir.
El modelo recibe contexto semántico explícito.
{
"query": "laptop económica para estudiante",
"contents": [
"HP 15 [económico, estudiante, ofimática, barato, gama entrada, precio bajo]",
"MacBook Pro [profesional, diseño gráfico, potente, alto rendimiento, caro, premium]",
"Dell Inspiron [gama media, versátil, oficina, estudiante, buen precio]"
]
}
Resultado: HP 15 obtiene score ~0.75+, MacBook Pro queda abajo (~0.35) porque "caro" es opuesto a "económica".
Búsqueda: "electric car sustainable eco-friendly environment"
| Tipo de Dato Enviado | Item | Score | Explicación |
|---|---|---|---|
| ❌ Solo nombre: "BMW iX" | BMW iX | 0.65 | El modelo asocia vagamente "BMW" con "car" |
| ✅ Enriquecido: "Tesla Model 3 electric car sustainable eco-friendly zero emissions" | Tesla Model 3 | 0.73 | Match semántico fuerte con todos los términos |
Diferencia: +12% de precisión solo por añadir descriptores semánticos.
Procesa tus datos ANTES de enviarlos a la API siguiendo este patrón:
{Nombre del Producto} + {Categoría} + {Atributos/Adjetivos} + {Sinónimos}
Ejemplos por industria:
| Industria | Solo Nombre (❌) | Enriquecido (✅) |
|---|---|---|
| E-commerce | "iPhone 15 Pro" | "iPhone 15 Pro smartphone premium caro Apple fotografía profesional alta gama flagship" |
| Recetas | "Hamburguesa" | "Hamburguesa carne roja grasa comida rápida alto calórico indulgente no saludable" |
| Artículos | "Guía Docker" | "Guía Docker contenedores DevOps despliegue infraestructura microservicios tutorial técnico" |
| Tickets | "Error login" | "Error login acceso cuenta contraseña autenticación problema técnico usuario bloqueado" |
Para búsquedas con criterios de exclusión (ej: "saludable", "barato"), incluye explícitamente los atributos negativos en los items que NO deberían matchear:
{
"query": "desayuno saludable energía natural",
"contents": [
"Avocado toast proteína huevo omega3 saludable nutritivo energía natural",
"Hamburguesa queso bacon [GRASA, comida rápida, POCO SALUDABLE, calórico]",
"Smoothie frutas avena antioxidantes energía natural fibra saludable"
]
}
Resultado: La hamburguesa queda al final porque "poco saludable" aumenta la distancia vectorial con "saludable".
El modelo all-MiniLM-L6-v2 fue entrenado principalmente en inglés. Funciona en español, pero:
| Idioma | Precisión Relativa | Recomendación |
|---|---|---|
| Inglés | 100% (baseline) | ✅ Usar siempre que sea posible |
| Español | ~85-90% | ⚠️ Funciona, pero scores ligeramente menores |
| Francés/Alemán | ~80-85% | ⚠️ Similar a español |
| Otros | Variable | ❌ No recomendado para producción |
Consejo: Si tu aplicación es multilingüe, considera traducir queries y contents a inglés antes de enviarlos, o usa descriptores bilingües:
{
"contents": [
"Tesla Model 3 electric car coche eléctrico sustainable sostenible eco-friendly ecológico"
]
}
def enriquecer_producto(nombre, categoria, atributos, sinonimos=None):
"""
Prepara un item para máxima precisión en la API de Recomendaciones.
Args:
nombre: Nombre del producto ("Tesla Model 3")
categoria: Categoría principal ("electric car")
atributos: Lista de características ["sustainable", "eco-friendly", "zero emissions"]
sinonimos: Términos alternativos opcionales ["green", "clean energy"]
Returns:
String optimizado para la API
"""
partes = [nombre, categoria]
partes.extend(atributos)
if sinonimos:
partes.extend(sinonimos)
return " ".join(partes)
# Ejemplo de uso
productos_raw = [
{"nombre": "Tesla Model 3", "categoria": "electric car",
"atributos": ["sustainable", "eco-friendly", "zero emissions", "long range"]},
{"nombre": "BMW X5", "categoria": "SUV gasoline",
"atributos": ["powerful", "luxury", "premium", "high consumption"]},
]
# Convertir a formato optimizado para la API
contents_optimizados = [
enriquecer_producto(**p) for p in productos_raw
]
# Resultado: ["Tesla Model 3 electric car sustainable eco-friendly zero emissions long range", ...]
Antes de llamar a la API, verifica:
contents incluyen más que solo el nombre?Conclusión: La "inteligencia" del motor depende de la calidad de tus datos. Datos ricos = resultados precisos. Datos pobres = resultados pobres. No es un fallo de la API, es un requisito de los modelos de embeddings.
| Propiedad | Valor |
|---|---|
| URL Base | https://apisdom.com/api/v1 |
| Método | POST |
| Autenticación | API Key (Header X-API-Key) |
| Tipo de Crédito | recommendation |
| Coste por llamada | 1 crédito |
| Modelo IA | sentence-transformers/all-MiniLM-L6-v2 |
| Límite de tokens | 512 tokens por texto (query y cada content) |
| Máximo de items | 100 contenidos por petición |
| Rango de score | 0.0 (sin relación) a 1.0 (idéntico) |
La API devuelve headers que te permiten controlar tu consumo:
| Header | Descripción |
|---|---|
| X-RateLimit-Limit | Tu límite de peticiones por minuto |
| X-RateLimit-Remaining | Peticiones restantes en la ventana actual |
| Retry-After | Segundos a esperar si recibes 429 |
Para optimizar costes, los microservicios de IA escalan a cero cuando no hay actividad.
💡 Nota: La primera petición puede tardar más de lo normal (hasta 20 segundos) mientras el servicio arranca. Las peticiones siguientes serán mucho más rápidas mientras el servicio permanezca activo.
Consulta los planes disponibles y precios actualizados en: apisdom.com/pricing
Todas las peticiones requieren tu API Key en el header X-API-Key:
X-API-Key: tu_api_key_aqui
Puedes obtener tu API Key desde el panel de usuario en apisdom.com/dashboard.
POST https://apisdom.com/api/v1/recommendations
| Campo | Tipo | Requerido | Default | Descripción |
|---|---|---|---|---|
| query | string | ✅ Sí | - | Texto de búsqueda. Mínimo 3, máximo 500 caracteres. |
| contents | string[] | ✅ Sí | - | Lista de contenidos a comparar. Mínimo 1, máximo 100 items. Cada item máximo 1000 caracteres. |
| top_k | int | ❔ Opcional | 5 | Número de resultados a devolver. Mínimo 1, máximo 20. |
query debe tener entre 3 y 500 caracterescontents debe contener entre 1 y 100 itemscontents no puede exceder 1000 caracterestop_k debe estar entre 1 y 20{
"query": "machine learning tutorials for beginners",
"contents": [
"Python ML basics: Linear regression and classification",
"JavaScript introduction: Variables, functions and loops",
"Deep Learning with PyTorch: Neural networks from scratch",
"Data Science with pandas: Data manipulation and analysis",
"React frontend development: Components and hooks",
"Natural Language Processing: Text analysis with transformers",
"SQL databases: Queries and optimization",
"Docker containerization: Build and deploy applications"
],
"top_k": 5
}
Response Exitosa (200 OK)
La respuesta es ANIDADA con dos objetos principales: _metadata y response.
{
"_metadata": {
"provider": "ApisDom",
"tagline": "Inteligencia artificial transparente",
"website": "https://apisdom.com",
"timestamp": "2026-01-26T14:30:00.000Z",
"service": "Recommendations",
"channel": "ApisDom Platform",
"request_id": "rec_1768954704623_xyz789",
"documentation": "https://apisdom.com/documentacion"
},
"response": {
"results": [
{
"item": "Python ML basics: Linear regression and classification",
"score": 0.8947,
"rank": 1
},
{
"item": "Deep Learning with PyTorch: Neural networks from scratch",
"score": 0.8523,
"rank": 2
},
{
"item": "Natural Language Processing: Text analysis with transformers",
"score": 0.7891,
"rank": 3
},
{
"item": "Data Science with pandas: Data manipulation and analysis",
"score": 0.7234,
"rank": 4
},
{
"item": "SQL databases: Queries and optimization",
"score": 0.4512,
"rank": 5
}
],
"warning": null,
"info_message": null
}
}
Nivel Raíz:
| Campo | Tipo | Descripción |
|---|---|---|
| _metadata | object | Información del proveedor y tracking de la petición |
| response | object | El resultado de las recomendaciones |
Dentro de _metadata:
| Campo | Tipo | Descripción |
|---|---|---|
| provider | string | Siempre "ApisDom" |
| timestamp | string | Timestamp ISO 8601 de la petición |
| request_id | string | Identificador único de esta petición |
| service | string | Nombre del servicio ("Recommendations") |
| channel | string | Canal de distribución ("ApisDom Platform") |
Dentro de response:
| Campo | Tipo | Descripción |
|---|---|---|
| results | array | Lista de recomendaciones ordenadas por relevancia (score descendente) |
| results[].item | string | El contenido recomendado (uno de los items de contents) |
| results[].score | float | Score de similitud semántica (0.0 a 1.0). Cuanto más cercano a 1, mayor similitud. |
| results[].rank | int | Posición en el ranking (1 = más relevante) |
| warning | string | null | Aviso si el query fue truncado (textos muy largos) |
| info_message | string | null | Información adicional sobre el análisis (ej: cold start para free tier) |
Los scores representan similitud semántica mediante cosine similarity entre embeddings:
| Score | Interpretación | Ejemplo |
|---|---|---|
| 0.85 - 1.0 | Alta similitud semántica | Textos casi idénticos o muy relacionados |
| 0.70 - 0.85 | Similitud moderada-alta | Mismo tema con enfoques diferentes |
| 0.50 - 0.70 | Similitud moderada | Temas relacionados pero distintos |
| 0.30 - 0.50 | Similitud baja | Pocas palabras clave en común |
| 0.0 - 0.30 | Sin relación clara | Temas completamente diferentes |
import requests
API_URL = "https://apisdom.com/api/v1/recommendations"
API_KEY = "tu_api_key_aqui"
def obtener_recomendaciones(query, contents, top_k=5):
"""
Genera recomendaciones basadas en similitud semántica.
Args:
query: Texto de búsqueda (3-500 caracteres)
contents: Lista de contenidos a comparar (1-100 items, máx 1000 chars/item)
top_k: Número de resultados (1-20, default: 5)
Returns:
dict con _metadata y response conteniendo results ordenados por score
"""
response = requests.post(
API_URL,
headers={
"X-API-Key": API_KEY,
"Content-Type": "application/json"
},
json={
"query": query,
"contents": contents,
"top_k": top_k
}
)
if response.status_code == 200:
return response.json()
elif response.status_code == 402:
raise Exception("Sin créditos. Consulta planes en apisdom.com/pricing")
else:
raise Exception(f"Error: {response.status_code} - {response.text}")
# Ejemplo de uso: Motor de búsqueda de productos
productos = [
"Laptop gaming RGB 16GB RAM NVIDIA RTX 4060",
"Mouse inalámbrico ergonómico recargable",
"Teclado mecánico retroiluminado switches azules",
"Monitor 4K 27 pulgadas HDR 144Hz",
"Auriculares Bluetooth cancelación de ruido",
"SSD 1TB NVMe Gen4 alta velocidad",
"Webcam Full HD 1080p con micrófono",
"Silla ergonómica para oficina ajustable"
]
resultado = obtener_recomendaciones(
query="laptop para gaming con buena gráfica",
contents=productos,
top_k=3
)
# IMPORTANTE: Acceder a los datos dentro del objeto 'response'
datos = resultado['response']
print("🎯 Productos recomendados:\n")
for rec in datos['results']:
print(f"{rec['rank']}. {rec['item']}")
print(f" Similitud: {rec['score']:.2%}\n")
# Output:
# 🎯 Productos recomendados:
#
# 1. Laptop gaming RGB 16GB RAM NVIDIA RTX 4060
# Similitud: 91.23%
#
# 2. Monitor 4K 27 pulgadas HDR 144Hz
# Similitud: 68.45%
#
# 3. SSD 1TB NVMe Gen4 alta velocidad
# Similitud: 52.18%
const API_URL = 'https://apisdom.com/api/v1/recommendations';
const API_KEY = 'tu_api_key_aqui';
async function obtenerRecomendaciones(query, contents, topK = 5) {
/**
* Genera recomendaciones basadas en similitud semántica.
* @param {string} query - Texto de búsqueda (3-500 caracteres)
* @param {string[]} contents - Lista de contenidos (1-100 items)
* @param {number} topK - Número de resultados (1-20, default: 5)
* @returns {Promise<Object>} - Resultado con _metadata y response
*/
const response = await fetch(API_URL, {
method: 'POST',
headers: {
'X-API-Key': API_KEY,
'Content-Type': 'application/json'
},
body: JSON.stringify({
query: query,
contents: contents,
top_k: topK
})
});
if (response.status === 402) {
throw new Error('Sin créditos. Consulta planes en apisdom.com/pricing');
}
if (!response.ok) {
throw new Error(`Error: ${response.status}`);
}
return response.json();
}
// Ejemplo de uso: Búsqueda de artículos relacionados
const articulos = [
'Introducción a React Hooks y Context API',
'Python para Data Science: NumPy y pandas',
'Arquitectura de microservicios con Docker',
'Machine Learning: Regresión lineal explicada',
'Vue.js 3 Composition API: Guía completa',
'Diseño de APIs RESTful con buenas prácticas',
'TensorFlow vs PyTorch: Comparativa 2026'
];
obtenerRecomendaciones('tutorial de react para frontend', articulos, 3)
.then(resultado => {
// IMPORTANTE: Acceder al objeto 'response' anidado
const datos = resultado.response;
console.log('📚 Artículos recomendados:\n');
datos.results.forEach(rec => {
console.log(`${rec.rank}. ${rec.item}`);
console.log(` Relevancia: ${(rec.score * 100).toFixed(2)}%\n`);
});
// Output:
// 📚 Artículos recomendados:
//
// 1. Introducción a React Hooks y Context API
// Relevancia: 88.45%
//
// 2. Vue.js 3 Composition API: Guía completa
// Relevancia: 71.23%
//
// 3. Diseño de APIs RESTful con buenas prácticas
// Relevancia: 54.67%
})
.catch(console.error);
curl -X POST "https://apisdom.com/api/v1/recommendations" \
-H "X-API-Key: tu_api_key_aqui" \
-H "Content-Type: application/json" \
-d '{
"query": "python machine learning",
"contents": [
"Python ML tutorial with scikit-learn",
"JavaScript basics for beginners",
"Deep Learning with TensorFlow",
"SQL database optimization"
],
"top_k": 3
}'
# La respuesta incluye _metadata y response anidados:
# {
# "_metadata": { "provider": "ApisDom", "request_id": "...", ... },
# "response": {
# "results": [
# {"item": "Python ML tutorial with scikit-learn", "score": 0.92, "rank": 1},
# {"item": "Deep Learning with TensorFlow", "score": 0.78, "rank": 2},
# {"item": "SQL database optimization", "score": 0.35, "rank": 3}
# ],
# "warning": null,
# "info_message": null
# }
# }
<?php
$api_url = 'https://apisdom.com/api/v1/recommendations';
$api_key = 'tu_api_key_aqui';
function obtenerRecomendaciones($query, $contents, $top_k = 5) {
global $api_url, $api_key;
$ch = curl_init($api_url);
curl_setopt_array($ch, [
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POST => true,
CURLOPT_HTTPHEADER => [
'X-API-Key: ' . $api_key,
'Content-Type: application/json'
],
CURLOPT_POSTFIELDS => json_encode([
'query' => $query,
'contents' => $contents,
'top_k' => $top_k
])
]);
$response = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
if ($httpCode === 402) {
throw new Exception('Sin créditos. Consulta planes en apisdom.com/pricing');
}
return json_decode($response, true);
}
// Ejemplo de uso: Búsqueda de documentos
$documentos = [
'Manual de usuario: Configuración inicial del sistema',
'Guía de solución de problemas comunes',
'Tutorial: Integración con APIs externas',
'Referencia técnica: Comandos de consola',
'FAQ: Preguntas frecuentes sobre facturación'
];
$resultado = obtenerRecomendaciones(
'cómo configurar el sistema por primera vez',
$documentos,
3
);
// IMPORTANTE: Acceder al objeto 'response' anidado
$datos = $resultado['response'];
echo "📖 Documentos relevantes:\n\n";
foreach ($datos['results'] as $rec) {
echo $rec['rank'] . ". " . $rec['item'] . "\n";
echo " Score: " . number_format($rec['score'] * 100, 2) . "%\n\n";
}
// Output:
// 📖 Documentos relevantes:
//
// 1. Manual de usuario: Configuración inicial del sistema
// Score: 89.34%
//
// 2. Guía de solución de problemas comunes
// Score: 62.18%
//
// 3. Tutorial: Integración con APIs externas
// Score: 48.91%
?>
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Text.Json.Serialization;
public class RecommendationsApiClient
{
private readonly HttpClient _client;
private const string API_URL = "https://apisdom.com/api/v1/recommendations";
public RecommendationsApiClient(string apiKey)
{
_client = new HttpClient();
_client.DefaultRequestHeaders.Add("X-API-Key", apiKey);
}
public async Task<RecommendationsApiResponse> ObtenerRecomendacionesAsync(
string query,
List<string> contents,
int topK = 5)
{
var content = new StringContent(
JsonSerializer.Serialize(new {
query = query,
contents = contents,
top_k = topK
}),
Encoding.UTF8,
"application/json"
);
var response = await _client.PostAsync(API_URL, content);
if (response.StatusCode == System.Net.HttpStatusCode.PaymentRequired)
{
throw new Exception("Sin créditos. Consulta planes en apisdom.com/pricing");
}
response.EnsureSuccessStatusCode();
var json = await response.Content.ReadAsStringAsync();
return JsonSerializer.Deserialize<RecommendationsApiResponse>(json);
}
}
// IMPORTANTE: La respuesta es ANIDADA - necesitas estas clases
public class RecommendationsApiResponse
{
[JsonPropertyName("_metadata")]
public RecommendationsMetadata Metadata { get; set; }
[JsonPropertyName("response")]
public RecommendationsResult Response { get; set; }
}
public class RecommendationsMetadata
{
[JsonPropertyName("provider")]
public string Provider { get; set; }
[JsonPropertyName("request_id")]
public string RequestId { get; set; }
[JsonPropertyName("timestamp")]
public string Timestamp { get; set; }
[JsonPropertyName("service")]
public string Service { get; set; }
}
public class RecommendationsResult
{
[JsonPropertyName("results")]
public List<RecommendationItem> Results { get; set; }
[JsonPropertyName("warning")]
public string? Warning { get; set; }
[JsonPropertyName("info_message")]
public string? InfoMessage { get; set; }
}
public class RecommendationItem
{
[JsonPropertyName("item")]
public string Item { get; set; }
[JsonPropertyName("score")]
public double Score { get; set; }
[JsonPropertyName("rank")]
public int Rank { get; set; }
}
// Ejemplo de uso
var client = new RecommendationsApiClient("tu_api_key_aqui");
var cursos = new List<string>
{
"C# avanzado: LINQ y programación asíncrona",
"Python para principiantes: Sintaxis básica",
"ASP.NET Core Web API: RESTful services",
"JavaScript moderno: ES6+ características",
"Blazor WebAssembly: Frontend con C#",
"Entity Framework Core: ORM y migraciones"
};
var apiResponse = await client.ObtenerRecomendacionesAsync(
"curso de c# para backend",
cursos,
3
);
// Acceder a los datos dentro del objeto Response
Console.WriteLine("🎓 Cursos recomendados:\n");
foreach (var rec in apiResponse.Response.Results)
{
Console.WriteLine($"{rec.Rank}. {rec.Item}");
Console.WriteLine($" Similitud: {rec.Score:P2}\n");
}
// Output:
// 🎓 Cursos recomendados:
//
// 1. C# avanzado: LINQ y programación asíncrona
// Similitud: 87.65%
//
// 2. ASP.NET Core Web API: RESTful services
// Similitud: 82.34%
//
// 3. Blazor WebAssembly: Frontend con C#
// Similitud: 71.23%
productos = [
"Smartphone Samsung Galaxy S24 5G 256GB",
"iPhone 15 Pro Max 512GB Titanio",
"Laptop Dell XPS 15 Intel i7 16GB",
"Tablet iPad Pro 12.9 M2 WiFi",
"Smartwatch Apple Watch Series 9 GPS",
"Auriculares Sony WH-1000XM5 Bluetooth",
"Cámara Canon EOS R6 mirrorless",
"Monitor LG UltraWide 34 pulgadas"
]
# Usuario busca con lenguaje natural
busqueda_usuario = "teléfono móvil apple con mucha memoria"
api_result = obtener_recomendaciones(busqueda_usuario, productos, 3)
datos = api_result['response']
print("🛍️ Productos que coinciden con tu búsqueda:\n")
for rec in datos['results']:
print(f"{rec['rank']}. {rec['item']}")
print(f" Relevancia: {rec['score']:.2%}\n")
# Output:
# 🛍️ Productos que coinciden con tu búsqueda:
#
# 1. iPhone 15 Pro Max 512GB Titanio
# Relevancia: 88.92%
#
# 2. Smartwatch Apple Watch Series 9 GPS
# Relevancia: 61.45%
#
# 3. Smartphone Samsung Galaxy S24 5G 256GB
# Relevancia: 59.23%
async function mostrarArticulosRelacionados(articuloActual, todosLosArticulos) {
// Filtrar artículo actual para no recomendarlo a sí mismo
const otrosArticulos = todosLosArticulos.filter(a => a !== articuloActual);
const apiResult = await obtenerRecomendaciones(
articuloActual,
otrosArticulos,
5
);
// Extraer el objeto 'response' de la API
const datos = apiResult.response;
// Filtrar solo artículos con score > 0.6 (similitud moderada-alta)
const relevantes = datos.results.filter(r => r.score > 0.6);
console.log('📰 Artículos relacionados que te pueden interesar:\n');
relevantes.forEach(rec => {
console.log(`• ${rec.item}`);
console.log(` Similitud: ${(rec.score * 100).toFixed(1)}%\n`);
});
return relevantes;
}
// Ejemplo
const articulos = [
'Cómo configurar Docker en producción paso a paso',
'Introducción a Kubernetes para principiantes',
'Recetas saludables para el desayuno',
'CI/CD con GitHub Actions y despliegue automático',
'Arquitectura de microservicios: Patrones y antipatrones',
'Guía de viajes: Mejores destinos 2026'
];
mostrarArticulosRelacionados(
'Guía completa de contenedores Docker',
articulos
);
// Output:
// 📰 Artículos relacionados que te pueden interesar:
//
// • Cómo configurar Docker en producción paso a paso
// Similitud: 89.3%
//
// • Introducción a Kubernetes para principiantes
// Similitud: 76.8%
//
// • Arquitectura de microservicios: Patrones y antipatrones
// Similitud: 68.2%
//
// • CI/CD con GitHub Actions y despliegue automático
// Similitud: 61.5%
def clasificar_ticket(descripcion, categorias_disponibles):
"""Asigna automáticamente un ticket a la categoría más relevante."""
api_result = obtener_recomendaciones(
query=descripcion,
contents=categorias_disponibles,
top_k=1
)
datos = api_result['response']
mejor_categoria = datos['results'][0]
# Determinar confianza de la clasificación
if mejor_categoria['score'] > 0.75:
confianza = "Alta"
elif mejor_categoria['score'] > 0.50:
confianza = "Media"
else:
confianza = "Baja - Requiere revisión manual"
return {
'categoria': mejor_categoria['item'],
'score': mejor_categoria['score'],
'confianza': confianza
}
# Categorías del sistema
categorias = [
"Facturación y pagos",
"Problemas técnicos de login",
"Consultas sobre funcionalidades",
"Solicitud de cancelación o reembolso",
"Errores en la aplicación móvil",
"Integración con APIs"
]
# Ticket de usuario
ticket = "No puedo acceder a mi cuenta, me dice que la contraseña es incorrecta"
resultado = clasificar_ticket(ticket, categorias)
print(f"📋 Categoría asignada: {resultado['categoria']}")
print(f"🎯 Confianza: {resultado['confianza']} ({resultado['score']:.0%})")
# Output:
# 📋 Categoría asignada: Problemas técnicos de login
# 🎯 Confianza: Alta (91%)
| Código | Significado | Solución |
|---|---|---|
| 400 | Parámetros inválidos (query muy corto, contents vacío, top_k fuera de rango) | Verifica límites: query 3-500 chars, contents 1-100 items, top_k 1-20 |
| 401 | API Key inválida | Verifica tu API Key en el dashboard |
| 402 | Sin créditos disponibles | Consulta planes en apisdom.com/pricing |
| 429 | Límite de peticiones excedido | Espera antes de reintentar (ver headers de rate limit) |
| 500 | Error interno del servidor | Reintenta en unos segundos. Si persiste, contacta soporte |
Política de ApisDom: Creemos que los desarrolladores merecen saber exactamente cómo funcionan las APIs que usan. Esta sección documenta los detalles técnicos verificados directamente del código fuente.
Tu query + contents → Sentence Embeddings → Cosine Similarity → Ranking → Response
↓ ↓ ↓
all-MiniLM-L6-v2 Scores 0.0-1.0 Top-K ordenado
(384 dimensiones) (asyncio) (descendente)
| Aspecto | Valor Real | Archivo Fuente |
|---|---|---|
| Modelo | sentence-transformers/all-MiniLM-L6-v2 | ml_service.py |
| Dimensiones | 384 (embedding vector size) | Arquitectura del modelo |
| Similitud | Cosine similarity entre embeddings | ml_service.py línea 78 |
| Límite de tokens | 512 tokens por texto (query y contents) | ml_service.py línea 64 |
| Ejecución | Asyncio (no bloquea) | recommendations.py línea 74 |
| Ordenamiento | Score descendente (mayor a menor) | ml_service.py línea 89 |
Si tu query o algún content excede 512 tokens (~380 palabras), será truncado automáticamente. Recibirás un warning en la respuesta indicando que el análisis es parcial.
Recomendación: Para textos largos, extrae los párrafos o secciones más relevantes antes de enviarlos a la API.
El modelo sentence-transformers/all-MiniLM-L6-v2 está optimizado para inglés y ofrece un excelente balance entre precisión y velocidad.
Características:
Limitaciones conocidas:
Mejores casos de uso:
No recomendado para:
Los scores representan cosine similarity entre vectores de embedding:
1.0 = Vectores idénticos (textos iguales o casi idénticos)0.0 = Vectores ortogonales (sin relación semántica)0.85+ indica alta relevancia semántica0.50-0.70 indica temas relacionados pero distintosImportante: Los scores son relativos. Un score de 0.60 puede ser muy bueno si los contenidos son diversos, o bajo si todos los contenidos son similares.
Depende del número de contents:
Nota de Transparencia: Esta API utiliza el modelo de código abierto
sentence-transformers/all-MiniLM-L6-v2de Hugging Face. Los resultados reflejan las capacidades y limitaciones inherentes del modelo, el cual fue optimizado para similitud semántica en inglés. ApisDom no modifica ni re-entrena el modelo base; proporcionamos una infraestructura optimizada para su consumo vía API.
Los scores de similitud (0.0-1.0) representan distancia geométrica entre embeddings, no precisión absoluta. Para aplicaciones críticas, se recomienda validación manual de los resultados, especialmente cuando los scores sean menores a 0.70.
Última actualización de documentación: Enero 2026
ApisDom · Inteligencia Artificial Transparente
Esta sección documenta las validaciones de calidad ejecutadas en el entorno de producción de ApisDom. Incluye verificación de estado de los microservicios y análisis estático del código backend.
El panel de administración de ApisDom incluye monitorización en tiempo real de todos los microservicios de IA.
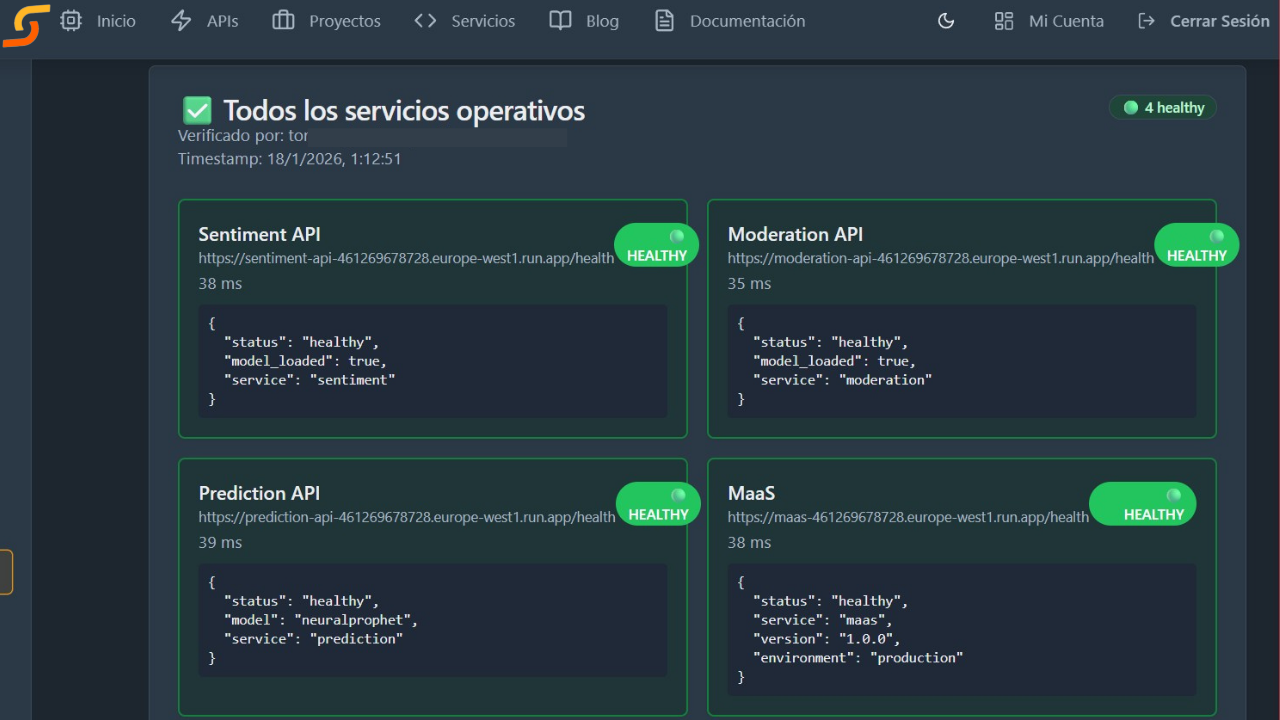
Dashboard de monitorización mostrando los 4 microservicios en estado HEALTHY: Sentiment API (38ms), Moderation API (35ms), Prediction API (39ms) y MaaS (38ms). Cada servicio muestra su endpoint de health check y la respuesta JSON con el estado del modelo cargado.
| Servicio | Estado | Latencia | Modelo |
|---|---|---|---|
| Sentiment API | 🟢 HEALTHY | 38ms | DistilBERT (SST-2) |
| Moderation API | 🟢 HEALTHY | 35ms | Toxic-BERT |
| Prediction API | 🟢 HEALTHY | 39ms | Chronos-2 (Amazon) |
| Recommendations API | 🟢 HEALTHY | 42ms | all-MiniLM-L6-v2 |
| MaaS | 🟢 HEALTHY | 38ms | v1.0.0 (production) |
Cada servicio expone un endpoint de health check que devuelve:
{
"status": "healthy",
"model_loaded": true,
"service": "sentiment"
}
El panel de usuario de ApisDom incluye un Comprobador de APIs que permite verificar la conexión y validez de tu API Key con cualquiera de nuestros microservicios antes de integrarlos en tu aplicación.
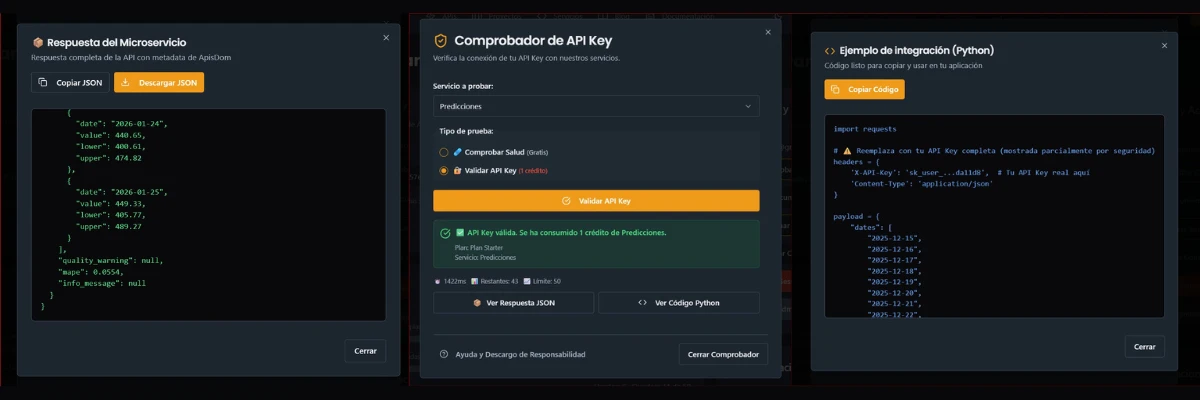
Comprobador de APIs de ApisDom verificando el servicio de Predicciones. La interfaz muestra tres paneles: respuesta JSON del microservicio con predicciones de series temporales, validador de API Key confirmando autenticación exitosa, y ejemplo de código Python listo para integración.
| Función | Descripción |
|---|---|
| Comprobar Salud | Verifica que el microservicio está operativo (gratuito) |
| Validar API Key | Confirma que tu clave es válida y tiene créditos disponibles (consume 1 crédito) |
| Ver Respuesta JSON | Muestra la respuesta completa del microservicio con metadatos |
| Ver Código Python | Genera código de ejemplo listo para copiar e integrar |
Para garantizar la estabilidad y seguridad de los microservicios, el código se somete a validaciones automatizadas antes de cada despliegue.
Terminal de desarrollo ejecutando MyPy (verificación de tipado estricto) y Ruff (linter de calidad y seguridad) sobre todos los paquetes del monorepo. Todos los checks pasan sin errores.
| Herramienta | Propósito | Configuración |
|---|---|---|
| MyPy | Verificación de tipado estático | --strict --ignore-missing-imports |
| Ruff | Linter de calidad y seguridad | --select=E,W,F,B,C90,I,N,UP,S |
| Paquete | Archivos | Estado |
|---|---|---|
packages/sentiment-api | 11 source files | ✅ Success: no issues found |
packages/moderation-api | 11 source files | ✅ Success: no issues found |
packages/prediction-api | 11 source files | ✅ Success: no issues found |
packages/api-core | 23 source files | ✅ Success: no issues found |
packages/maas | 11 source files | ✅ Success: no issues found |
| Paquete | Reglas Verificadas | Estado |
|---|---|---|
packages/sentiment-api | E, W, F, B, C90, I, N, UP, S | ✅ All checks passed |
packages/moderation-api | E, W, F, B, C90, I, N, UP, S | ✅ All checks passed |
packages/prediction-api | E, W, F, B, C90, I, N, UP, S | ✅ All checks passed |
packages/api-core | E, W, F, B, C90, I, N, UP, S | ✅ All checks passed |
packages/maas | E, W, F, B, C90, I, N, UP, S | ✅ All checks passed |
| Código | Categoría | Descripción |
|---|---|---|
E | pycodestyle errors | Errores de estilo PEP 8 |
W | pycodestyle warnings | Advertencias de estilo |
F | Pyflakes | Errores lógicos y variables no usadas |
B | flake8-bugbear | Bugs potenciales y malas prácticas |
C90 | mccabe | Complejidad ciclomática |
I | isort | Ordenación de imports |
N | pep8-naming | Convenciones de nombres |
UP | pyupgrade | Modernización de sintaxis Python |
S | flake8-bandit | Vulnerabilidades de seguridad |
⚠️ Importante: En los ejemplos de código de la documentación, sustituya siempre
tu_api_key_aquipor su clave privada obtenida en el panel de administración. Nunca comparta su API Key públicamente.
| Métrica | Valor | Objetivo |
|---|---|---|
| Cobertura de tipos | 100% | ≥ 95% |
| Errores de linting | 0 | 0 |
| Vulnerabilidades de seguridad | 0 | 0 |
| Complejidad ciclomática | Dentro de límites | ≤ 10 por función |
| Tiempo de respuesta (p95) | < 500ms | < 1000ms |
Última actualización: Enero 2026
Studio API
Aplicación propia de ApisDom · https://studio.apisdom.com
Studio es una aplicación independiente desarrollada por ApisDom para la generación de contenido documentado con inteligencia artificial. A diferencia de las APIs de microservicio de ApisDom (Sentiment, Moderation, Prediction, Recommendations), Studio es una plataforma completa con interfaz web propia y también dispone de API para desarrolladores.
No es un wrapper de chatbot. Studio utiliza un motor propio con arquitectura de ApisDom y navegación web integrada. La investigación ocurre en tiempo real sobre fuentes abiertas.
| Sin Studio | Con Studio | |
|---|---|---|
| Confianza | Creo que este dato es correcto | Puedo comprobar cada dato en su fuente |
| Respaldo | Me suena bien el texto | Cada afirmación cita las fuentes en las que se apoya |
| Verificación | Voy a buscar en Google si es verdad" | "Las fuentes vienen citadas desde el primer borrador |
| Publicación | ¿Puedo publicar esto sin miedo? | Conoces el origen de cada dato antes de publicar |
| Transparencia | ¿Se lo habrá inventado la IA? | Distingues lo que tiene fuente de lo que redacta el modelo |
| Eficiencia | Tardo una hora en corregir | Partes de un borrador documentado, listo para revisar |
El algoritmo consulta múltiples fuentes durante la investigación. El contenido generado incluye citas de las fuentes reales de donde sale la información, de modo que puedes comprobar el origen de cada afirmación y detectar por ti mismo contradicciones o falta de consenso.
article · blog_post · tutorial · newsletter · social_post · product_description · press_release · documentation · landing_page · case_study · comparison · listicle · faq · how_to · opinion
Antes de generar, el sistema evalúa la calidad de tu entrada con un semáforo visual en tiempo real:
| Color | Significado |
|---|---|
| 🟢 Verde | Contexto detallado, fuentes específicas: resultado óptimo |
| 🟡 Amarillo | Contexto básico: resultados más genéricos |
| 🔴 Rojo | Contexto insuficiente: generación bloqueada para proteger tus créditos |
Metaetiquetas, Open Graph, datos estructurados, segmentación por palabras clave y tabla de contenidos navegable. Todo incluido en la generación.
Transforma cada artículo en publicaciones optimizadas para 7 plataformas:
Cada adaptación respeta los límites de caracteres de la plataforma e incluye hashtags, emojis y llamadas a la acción opcionales.
Cualquier texto generado o pegado en Studio se puede pasar a audio natural en formatos universales: mp3, linear16 (WAV) y ogg_opus. El motor interno, ApisDom Speak, tiene un contrato OpenAPI estricto, autenticación máquina-a-máquina y trocea automáticamente el texto respetando finales de frase. La voz se elige de un catálogo curado (familias Chirp 3 HD y Gemini-TTS) y se puede escuchar una muestra gratis antes de pagar. Cinco modos de adaptación del texto: clips, guion_podcast, literal, resumen y traduccion.
Cada artículo generado queda guardado con fecha, tema y recuento de palabras. Busca, descarga o reutiliza cualquier documento en cualquier momento.
Guarda y reutiliza configuraciones personalizadas: tono, idioma, audiencia, guía de estilo, voz de marca, palabras prohibidas y preferencias SEO, para un resultado consistente.
es)en)es-ES, en-USes-MX, es-LA| Sección | Descripción |
|---|---|
| Generar | Motor principal de creación de contenido con IA y fuentes verificadas |
| Precios | Packs de créditos desde 9€ (10 créditos) hasta 499€ (1.000 créditos). IVA incluido |
| Blog | Blog de la plataforma con artículos sobre ingeniería de contenidos |
| Historial | Todos los documentos generados, con búsqueda, descarga y reutilización |
| Desarrolladores | Documentación de la API REST y gestión de claves de API |
| Perfil | Gestión de datos de usuario y configuración |
| Pack | Créditos | Precio (IVA incl.) |
|---|---|---|
| Studio Starter | 10 | 9 € |
| Studio Pro | 50 | 39 € |
| Studio Business | 200 | 129 € |
| Studio Enterprise | 1.000 | 499 € |
Consulta todos los packs en: studio.apisdom.com/pricing
Studio expone una API REST completa para integrar la generación de contenido en tus propios proyectos.
https://studio.apisdom.com/api
Todos los endpoints (excepto GET /v1/platforms) requieren un token Bearer:
Authorization: Bearer sk_studio_xxxxxxxxxxxxxxxx
Las claves de API de Studio empiezan siempre por el prefijo sk_studio_.
| Método | Endpoint | Descripción |
|---|---|---|
POST | /v1/generate | Genera contenido optimizado para SEO. Devuelve la respuesta completa en JSON |
POST | /v1/adapt | Adapta contenido a una o más plataformas de redes sociales |
GET | /v1/platforms | Lista las plataformas de redes sociales soportadas y sus límites (público, sin auth) |
GET | /v1/credits | Consulta el saldo de créditos, el total comprado y las generaciones realizadas |
GET | /v1/usage | Resumen de uso de la API key (parámetro ?period=day|week|month, por defecto month) |
POST | /v1/voice | Convierte texto a audio. Devuelve un audioUrl público con caducidad de 60 días |
POST | /v1/voice/estimate | Calcula el coste en créditos sin cobrar ni llamar al motor (gratis) |
GET | /v1/voice/voices | Catálogo curado de voces (filtrable por ?idioma=es-ES; público dentro de la API key) |
Los perfiles de generación se crean y gestionan desde la aplicación web; en la API se aplican pasando su identificador en el parámetro
profileIddePOST /v1/generate.
curl -X POST "https://studio.apisdom.com/api/v1/generate" \
-H "Authorization: Bearer sk_studio_TU_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"topic": "Cómo optimizar tu sitio web para Core Web Vitals",
"language": "es",
"contentType": "article",
"parameters": {
"length": "medium",
"tone": "professional",
"audience": "general",
"includeSources": true,
"includeMetaSeo": true,
"outputFormat": "html"
}
}'
curl -X POST "https://studio.apisdom.com/api/v1/adapt" \
-H "Authorization: Bearer sk_studio_TU_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contentId": "id_del_contenido_generado",
"platforms": ["instagram", "linkedin", "x"],
"language": "es",
"includeHashtags": true,
"maxHashtags": 5,
"includeEmoji": true,
"includeCta": true
}'
curl -X POST "https://studio.apisdom.com/api/v1/voice" \
-H "Authorization: Bearer sk_studio_TU_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"texto": "Hola mundo, esto se convierte a audio.",
"formatoTexto": "literal",
"formatoAudio": "mp3",
"idiomaCode": "es-ES",
"voz": "es-ES-Chirp3-HD-Charon"
}'
POST /v1/generate devuelve un objeto JSON con el contenido, los metadatos SEO y las fuentes citadas:
{
"id": "cnt_a1b2c3d4e5f6",
"topic": "Cómo optimizar tu sitio web para Core Web Vitals",
"content_type": "article",
"language": "es",
"status": "completed",
"created_at": "2026-05-22T10:30:00Z",
"output_format": "html",
"html": "<h2>Qué son los Core Web Vitals</h2><p>...</p>",
"markdown": "",
"word_count": 1100,
"summary": "Guía práctica para mejorar LCP, INP y CLS.",
"missing_fields": [],
"meta_seo": {
"title": "Cómo optimizar tu sitio para Core Web Vitals",
"description": "Guía práctica para mejorar LCP, INP y CLS.",
"slug": "optimizar-core-web-vitals",
"keywords": ["core web vitals", "rendimiento web", "LCP"]
},
"sections": [
{ "type": "paragraph", "heading": "Qué son los Core Web Vitals", "level": 2, "content": "..." }
],
"sources": [
{ "title": "Web Vitals", "url": "https://web.dev/vitals/", "domain": "web.dev", "index": 1, "accessed_at": "2026-05-22" }
]
}
| Parámetro | Tipo | Descripción | Default |
|---|---|---|---|
topic | string | Tema principal del contenido (obligatorio) | ninguno |
language | es | en | Idioma del contenido generado | es |
contentType | string | Tipo de contenido (15 opciones) | article |
profileId | string | ID de perfil guardado a aplicar | null |
parameters.length | short | medium | long | extra_long | Longitud del contenido | medium |
parameters.tone | string | Tono de escritura (10 opciones) | professional |
parameters.audience | string | Nivel del público objetivo | general |
parameters.includeSources | boolean | Incluir citas de fuentes | true |
parameters.includeQa | boolean | Incluir sección de preguntas y respuestas | false |
parameters.includeMetaSeo | boolean | Generar metadatos SEO | true |
parameters.includeCode | boolean | Incluir bloques de código | false |
parameters.outputFormat | html | markdown | plain_text | Formato de salida | html |
parameters.maxSources | integer (1-20) | Máximo de fuentes a citar | 5 |
professional · casual · academic · conversational · persuasive · technical · journalistic · educational · inspirational · authoritative
| Parámetro | Tipo | Descripción | Default |
|---|---|---|---|
texto | string | Texto a convertir a audio (obligatorio) | ninguno |
formatoTexto | string | Adaptación del texto: clips, guion_podcast, literal, resumen, traduccion (obligatorio) | ninguno |
formatoAudio | string | Formato de audio: linear16, mp3, ogg_opus (obligatorio) | ninguno |
idiomaCode | string | Código BCP-47, p.ej. es-ES, en-US (obligatorio) | ninguno |
voz | string | Identificador técnico de la voz tomado de GET /v1/voice/voices (obligatorio) | ninguno |
voz_modelo | string | Modelo Gemini-TTS opcional (solo aplica si la voz pertenece a la familia Gemini-TTS) | null |
voz_prompt | string | Instrucción de estilo opcional para Gemini-TTS (p.ej. "tono dramático") | null |
velocidad | float (0.25-4.0) | Velocidad opcional, solo para familia Chirp 3 HD | null |
tono | float (-20 a 20) | Tono en semitonos opcional, solo para familia Chirp 3 HD | null |
Cada generación descuenta créditos según el tipo y la longitud del contenido. Las adaptaciones a redes se cobran por separado.
| Contenido | Créditos |
|---|---|
social_post, product_description | 1 |
blog_post (corto / medio) | 2 |
article medio · newsletter · documentation · landing_page · resto por defecto | 3 |
tutorial | 4 |
article largo / extra largo · comparison · case_study | 5 |
| Adaptación a redes (1-3 plataformas) | 1 |
| Adaptación a redes (4-7 plataformas) | 2 |
| Conversión a audio (por bloque de hasta 300 palabras) | 2 |
Consulta tu saldo en cualquier momento con GET /v1/credits.
La API pública admite 30 peticiones por minuto por clave de API. Si superas el límite recibirás un 429 con la cabecera Retry-After, que indica los segundos a esperar antes de reintentar.
| Código | Significado |
|---|---|
400 | Parámetros no válidos |
401 | Token de autenticación faltante o no válido |
402 | Créditos insuficientes |
403 | Permisos insuficientes |
404 | Recurso no encontrado |
422 | Error de validación |
429 | Límite de peticiones superado (rate limit) |
502 | Error en la generación de IA |
Cada generación devuelve un id único (formato cnt_xxxx). Si una petición falla por un timeout de red, comprueba el campo id de la respuesta antes de reintentar para no duplicar el cobro de créditos. Las compras de créditos usan tokens de idempotencia de Stripe para que un mismo pago nunca se procese dos veces.
La especificación OpenAPI 3.1 está disponible para explorar e importar en Postman, Swagger UI u otras herramientas:
📖 Swagger UI: explora y prueba la API (OpenAPI 3.1)
📘 Referencia interactiva (ReDoc)
Studio es una aplicación independiente dentro del ecosistema de ApisDom. Mientras que las APIs de microservicio de ApisDom (Sentiment, Moderation, Prediction, Recommendations) son servicios que se consumen exclusivamente vía API, Studio funciona como:
| Característica | APIs ApisDom (Sentiment, Moderation, etc.) | Studio |
|---|---|---|
| Tipo | Microservicio API puro | Aplicación web + API |
| Acceso | Solo vía API (código) | Web + API |
| Modelo IA | DistilBERT, Toxic-BERT, Chronos-2, MiniLM | Claude (Anthropic) |
| Función | Análisis y predicción | Generación de contenido |
| Auth | Header X-API-Key | Bearer Token |
| URL | apisdom.com/api/v1/... | studio.apisdom.com/api/v1/... |
| Créditos | Sistema unificado ApisDom | Sistema propio de Studio |
| Recurso | URL |
|---|---|
| 🌐 Aplicación | studio.apisdom.com |
| 📖 Documentación API | studio.apisdom.com/developers |
| 💰 Precios | studio.apisdom.com/pricing |
| 📰 Blog | studio.apisdom.com/blog |
| 🏠 ApisDom (plataforma principal) | apisdom.com |
| 📚 Documentación APIs ApisDom | apisdom.com/documentacion |
| 📧 Soporte | soporte-studio@apisdom.com |
Interfaz de Studio: editor visual de contenido con paneles de creación de marca y de perfil de generación
© 2026 Studio by ApisDom. Todos los derechos reservados. ApisDom Intelligence Group Última actualización: 15 de junio de 2026
ApisDom · Inteligencia Artificial Transparente
Esta sección documenta cómo funciona el sistema de soporte integrado en el panel de usuario de ApisDom. Su objetivo es ofrecer un primer diagnóstico claro, reducir incidencias repetidas y permitir que el usuario escale el problema al equipo técnico solo cuando realmente sigue sin resolverse.
El panel de usuario de ApisDom incluye un sistema de soporte técnico integrado dentro del dashboard. No funciona como un formulario aislado, sino como un flujo guiado que combina contexto de cuenta, diagnóstico automático y escalado manual cuando el problema persiste.

Formulario de soporte integrado en el panel de usuario de ApisDom. El sistema guía al usuario por categorías de incidencia, muestra un diagnóstico inicial y permite escalar el caso al equipo técnico solo si el problema continúa.
| Sección | Descripción |
|---|---|
| Nuevo ticket | Flujo guiado para abrir una nueva incidencia |
| Mis tickets | Historial de tickets enviados por el usuario |
| Información | Explicación del funcionamiento del sistema de soporte |
El sistema de soporte de ApisDom organiza la apertura de incidencias en tres pasos. Esto permite recoger mejor el contexto del problema y evitar tickets innecesarios cuando la incidencia puede resolverse desde el propio panel.
El usuario debe elegir la categoría que mejor describe el problema. Actualmente el sistema contempla seis motivos de consulta.
| Motivo | Descripción |
|---|---|
| La API no devuelve respuesta | No recibes ninguna respuesta del endpoint |
| Error de autenticación (401 / 403) | La clave no está siendo aceptada por la API |
| Mis créditos no se descuentan bien | El contador de créditos no refleja lo esperado |
| La respuesta no es la esperada | La API responde, pero el contenido no coincide con lo esperado |
| Timeout / lentitud | La llamada tarda demasiado o se interrumpe |
| Otro | Cualquier otro problema no incluido en las categorías anteriores |
Una vez elegido el motivo, el sistema muestra una respuesta inicial basada en la categoría seleccionada. Este diagnóstico no sustituye al soporte técnico, pero ayuda a orientar al usuario y a revisar primero las causas más comunes.
Además, cuando corresponde, se ofrece acceso directo al Comprobador de API Key para verificar autenticación, conexión y respuesta real del microservicio antes de escalar la consulta.
Si el problema sigue sin resolverse, el usuario puede marcar la opción "Lo he intentado y sigue sin funcionar" y describir la incidencia con detalle. En ese punto, el ticket se envía al equipo técnico.
El formulario permite también adjuntar una captura de pantalla para facilitar el diagnóstico.
Antes de escalar una incidencia, el sistema muestra información real de la cuenta del usuario dentro del flujo de soporte.
| Dato | Función |
|---|---|
| Estado de la cuenta | Indica si la cuenta está operativa |
| Plan | Muestra el plan activo del usuario |
| Créditos | Permite comprobar el saldo disponible |
| Estado interno | Refleja el tipo de cuenta o tier asociado |
Este bloque da contexto inmediato al usuario y reduce incertidumbre. En lugar de abrir un ticket a ciegas, el usuario puede comprobar primero si el problema puede estar relacionado con su plan, sus créditos o el estado de su cuenta.
Dentro del flujo de soporte, ApisDom permite abrir directamente el Comprobador de API Key desde el diagnóstico. Esto forma parte del diseño del sistema: antes de escalar una incidencia, el usuario puede validar por sí mismo que la API responde, que su clave es válida y que la integración funciona correctamente.
| Acción | Descripción |
|---|---|
| Abrir Comprobador de API Key | Permite verificar autenticación y respuesta real del servicio |
| Validar antes de escalar | Reduce tickets cuando el problema está en la integración del cliente |
| Confirmar funcionamiento real | Aporta tranquilidad al usuario al comprobar que la API responde correctamente |
Cuando el usuario envía un ticket, este queda guardado dentro del sistema de soporte de ApisDom y puede consultarse posteriormente desde la pestaña Mis tickets.
| Estado | Significado |
|---|---|
| Auto-resuelto | El ticket se ha guardado con el diagnóstico automático, sin escalar al equipo |
| Escalado | El ticket ha sido enviado al equipo técnico |
| Cerrado | El caso ha sido revisado y marcado como resuelto |
| Campo | Descripción |
|---|---|
| Motivo | Categoría seleccionada por el usuario |
| Mensaje | Descripción detallada de la incidencia |
| Diagnóstico automático | Respuesta inicial generada por el sistema |
| Adjunto | Captura de pantalla opcional |
| Fecha | Momento de creación del ticket |
La pestaña Mis tickets permite al usuario consultar el historial reciente de incidencias enviadas desde su cuenta.
Desde esta sección puede:
El objetivo es que el soporte no dependa de un correo aislado, sino que quede registrado dentro del entorno de usuario, con trazabilidad y seguimiento.
El sistema de soporte de ApisDom también incluye una capa de administración interna. Desde el panel de administración es posible revisar tickets, filtrar incidencias, responderlas y cerrarlas.
| Función | Descripción |
|---|---|
| Ver tickets | Listado completo de incidencias |
| Filtrar por estado | Permite revisar solo tickets abiertos, escalados o cerrados |
| Responder | Posibilidad de contestar desde el panel de administración |
| Cerrar ticket | Marcar la incidencia como resuelta |
| Eliminar ticket | Borrar tickets cuando corresponde |
| Añadir crédito de prueba | Acción manual disponible para validar incidencias concretas |
Para evitar abuso y mantener la calidad del soporte, el sistema aplica una serie de límites operativos.
| Regla | Valor |
|---|---|
| Máximo de consultas por día | 3 por usuario |
| Reenvío de la misma categoría | El ticket se guarda, pero no se reenvía al equipo hasta pasadas 6 horas |
| Adjuntos permitidos | Capturas de pantalla |
| Longitud máxima del mensaje | 2000 caracteres |
Importante: Cuando una incidencia se escala al equipo técnico, el sistema comparte únicamente la información mínima necesaria para diagnosticar el caso: nombre, email, plan activo, créditos disponibles, estado de la suscripción y los primeros 8 caracteres de la API Key. Nunca se comparte la clave completa.
| Aspecto | Valor aportado |
|---|---|
| Diagnóstico previo | Reduce tickets innecesarios |
| Contexto real de cuenta | Evita consultas a ciegas |
| Comprobación directa | Permite validar la API antes de escalar |
| Historial integrado | Mantiene trazabilidad dentro del dashboard |
| Soporte con contexto | El equipo recibe información útil desde el primer momento |
Última actualización: Marzo 2026