
El código de IA no se escribe, se hereda
La IA escribe rápido pero el mantenimiento llega después. Qué es la deuda de comprensión, qué dicen los estudios y cómo decidir antes de aceptar su código.

TL;DR: El código se escribe rápido y se mantiene despacio. La IA ha cambiado la primera parte. La segunda sigue intacta. Y por ese hueco es por donde te entran trozos sin padre al repo. Compilan. Pasan tests. Son tuyos durante cinco años. La factura no llega en el mes uno. Llega en el dos. Lo cuento como me lo he ido encontrando yo y como se lo he visto a otros, con números encima de la mesa y un caso de doce días que resume el problema entero.
Mes uno parece magia, mes seis ya no
Si llevas un rato dejando que la IA te escriba código en producción, ya conoces la película. Mes uno parece magia. PRs que entran rápido. Tests que pasan. Capturas para LinkedIn. El mánager respira. Hay quien escribe un post titulado cómo multiplicamos por tres la velocidad y se queda tan ancho.
Mes tres alguien se toca la barbilla. Aparece un bug raro. Abres git blame y ves un commit tuyo de hace dos meses. No te suena la función. La generó la IA aquel jueves a las cinco de la tarde. Tests pasan. Compila. Y la lógica que tienes delante no encaja con cómo está hecho el resto del sistema. El que firmo el commit no se acuerda. El que se acuerda eres tú, ahora, mirando una pantalla a las once de la noche.
Mes seis es cuando la sangre llega al río.
Ahí aparece, sin avisar, lo que da título a esto. El código generado por IA no se escribe. Se hereda. Lo que entra a tu repo son trozos sin padre. Funcionan. Compilan. Pasan CI. Y son tuyos para mantenerlos los próximos cinco años. Cambiar escritura por herencia parece un buen trato durante el primer trimestre. En el segundo año la factura tiene cara.
Los partes del día a día ya lo cantan. El riesgo no es un trasto fallando a lo loco. Es la facilidad para meter trozos sin dueño por cuatro duros y dejar a la IA tocando la pasta, los datos o lo delicado a pelo. Sin un triste filtro en medio que te pida los papeles, cuadre las reglas y ate corto lo que sale. Eso es lo que se hereda. Una pila de decisiones que nadie tomó del todo. El diagnóstico general de esa fragilidad operativa lo desarrollé en otro artículo del blog, La realidad de la IA: límites y fragilidad operativa, por si interesa el cuadro completo antes de seguir.
Lo que viene a continuación no es opinión mía. Son formas diferentes de medir lo mismo y las tres llegan a Roma.
Tres formas distintas de mirar y la misma respuesta
Cuento la primera. METR. Año 2025. Cogen a 16 desarrolladores con cinco años de media en sus propios repos. Repos grandes, miles de estrellas, un millón de líneas. Les dan 246 tareas de su backlog. La mitad las hacen con Cursor y Claude. La otra mitad a pelo. Cronómetro. Eso es todo.
Antes de empezar, esos devs predijeron que la IA les haría un 24% más rápidos. Cuando acabaron, todavía creían que les había hecho un 20% más rápidos. La realidad medida con el cronómetro fue 19% más lentos. Treinta y nueve puntos de diferencia entre lo que sintieron y lo que pasó. METR repitió en febrero de 2026 con más gente y más repos. El efecto se mantuvo. Es la escena del que sale del gimnasio convencido de que ha levantado más peso que ayer, mira la libreta y no.
Segunda forma. GitClear no encuesta ni mide tiempo. Mira código. Cinco años de código. 211 millones de líneas en miles de repos. Ve qué pasa cuando un commit entra. El refactor, que en 2021 era una de cada cuatro líneas modificadas, en 2024 baja a una de cada diez. El copy-paste sube del 8.3% al 12.3%. Y el churn, lo que se reescribe en menos de dos semanas, casi se dobla. 2024 es el primer año medido en que se copia más código del que se refactoriza. Eso no se discute. Es leer lo que el código hace, no lo que los devs sienten.
Tercera. La encuesta anual de Stack Overflow. 49.000 desarrolladores de 177 países en 2025. Aviso de entrada: Stack Overflow recluta por sus propios canales, ahí hay sesgo, y solo un tercio contestó las preguntas específicas de IA. Lo digo y sigo. Los números pegan igual. 84% usa o piensa usar IA. La confianza en la precisión se cayó de 40% a 29% en un año. El 46% activamente desconfía. El 66% dice que pierde más tiempo arreglando código casi correcto del que tardaría escribiéndolo. Y los devs senior son los que menos se fían: 2.6% confía plenamente.
Tres pruebas. Una con cronómetro. Otra leyendo código bruto. La tercera preguntando a 49.000 personas. Las tres apuntan al mismo sitio desde tres direcciones. La productividad que se siente no es la que se mide. El código que entra es de peor estructura. Los devs que más saben son los que más recelan.
La deuda que no salta en los builds
La deuda técnica de toda la vida la conocemos. Salta. Builds lentos. Dependencias enredadas. Ese módulo que nadie quiere tocar y se lo pasan unos a otros.
Lo nuevo es otra cosa. Lo bautizó este marzo de 2026 un ingeniero de Google, Addy Osmani: **deuda de comprensión.**La brecha entre cuánto código hay en tu sistema y cuánto entiende de verdad alguien del equipo.
La diferencia con la deuda técnica clásica es de calle. La deuda técnica grita. La deuda de comprensión calla. Tests pasan. PRs se mergean. Y cuando alguien pregunta cómo funciona aquello, miradas a la mesa. No se nota hasta que un cambio simple revienta tres cosas que parecían sin relación.
Pónlo así. Una cinta de fábrica soltando piezas a velocidad china. Al final, un señor con bata mirando una pieza por minuto. Las que llegan, llegan. Solo se entienden las que logra mirar a tiempo. El resto pasa al almacén sin revisar. El almacén es nuestro repositorio.
Los números que da Osmani son crudos. Una IA suelta 140-200 líneas significativas por minuto. Un humano comprende 20-40. Escupe cinco veces más rápido de lo que un cerebro asimila. Por ahí entra todo lo demás.
Osmani cuenta también un caso documentado por Margaret-Anne Storey, una profesora de Victoria especializada en cómo trabajan los devs. Un equipo de estudiantes usó IA todo el proyecto. Semana siete, contra el muro de hormigón. Sin pintar. Cambios pequeños empezaron a romper cosas grandes. Nadie del equipo entendía por qué el sistema estaba hecho así. La justificación de de las decisiónes se habían evaporado por el camino. Avance rápido al principio, parálisis y frenazo en seco a las siete semanas.
Y luego está el detalle que tiene gracia. El 29 de enero de 2026, en arXiv 2601.20245, sale un estudio firmado por Judy Hanwen Shen y Alex Tamkin, de Anthropic. 52 ingenieros que ya usaban Python aprendiendo Trio, una librería que no conocían. Mitad con IA. Mitad a pelo. Los que usaron IA acabaron solo un pelín antes, sin ganancia de tiempo que cuente. Pero puntuaron un 17% peor en el examen de comprensión posterior. El propio estudio dice que la IA daña la comprensión conceptual, la lectura de código y el debugging. Justo lo que necesitas cuando el código falla.
Que ese estudio lo publique la propia casa que vende uno de los productos top del mercado tiene su gracia amarga. O hay honestidad inusual o hay otra cosa que se me escapa. Cada cual que decida.
La factura llega en el año dos
A esta altura entran los números económicos. byteiota, un medio especializado, recopiló en marzo de 2026 varias mediciones que vale la pena juntar. Aviso de entrada: byteiota agrega datos de otros (LinearB, CodeRabbit), no es un paper propio. Le bajo el peso. Pero las cifras cuadran con lo demás. El análisis de CodeRabbit da 1.7 veces más issues por PR en código IA: 10.83 contra 6.45. La deuda técnica crece entre 30% y 41% tras adoptar IA. Y, sobre 8.1 millones de pull requests medidos por LinearB, el tiempo de ciclo completo sube con la IA, no baja. Otra vez lo mismo.
Lo más fuerte del agregado es la curva temporal. Año uno: parece que se entrega más. Año dos: el coste de mantenimiento se cuadruplica. Cuatro veces. Hay una frase de Armando Solar-Lezama, profesor del MIT, dicha al Wall Street Journal, que lo deja claro: la IA es como una tarjeta de crédito nueva que te deja acumular deuda técnica de formas que antes no podías. No es académica. Es contable. Se entiende a la primera. Es pagar el café al contado o tirar del plástico con un interés del que no te has leído la letra pequeña.
Forrester dice que el 75% de los decisores tecnológicos tendrán deuda técnica moderada o severa en 2026. Gartner dice que el enfoque prompt-to-app multiplicará los defectos de software por 25 antes de 2028. Son proyecciones de consultora, no medidas, y así las cito. Pero el sentido va por el mismo carril. Hay un patrón repitiéndose en muchos sitios a la vez.
Y luego está McKinsey. En su encuesta a directores de tecnología, esos directores calcularon que la deuda técnica equivale a entre el 20% y el 40% del valor de todo su parque tecnológico antes de amortizar. Y que entre el 10% y el 20% del presupuesto destinado a productos nuevos se va, en realidad, a tapar agujeros de deuda vieja. No a mejorar nada. A que la cosa no se caiga. Si la IA dobla o cuadruplica esa deuda en dos años, traducidme eso a euros vosotros mismos.
Lo que dicen los que venden la herramienta
A esta altura te van a salir dos números enfrente. Los saca cualquiera que venda IA para código. Vamos a mirarlos uno a uno.
El primero es el famoso 55.8% más rápido. Y lo primero que hay que decir es de cuándo es: febrero de 2023. Tres años, con todo lo que ha cambiado la IA de programar desde entonces, y se sigue agitando como si fuera de ayer. Es el estudio Peng et al. Lo firman Sida Peng (Microsoft Research), Eirini Kalliamvakou y Peter Cihon (GitHub) y Mert Demirer (MIT Sloan). 95 devs escribiendo un servidor HTTP en JavaScript desde cero. Una tarea aislada, de dos horas, sin equipo, sin código heredado, sin mantenimiento posterior. El grupo con Copilot tardó 1h11min. El grupo sin Copilot, 2h41min. Significativo, p-valor 0.0017.
Lo que el marketing no enseña es la letra pequeña. El intervalo de confianza al 95% va del 21% al 89%. Es un rango enorme. El 55.8% es la mediana de un cubo gigante. Sirve para titular un keynote, no para tomar una decisión empresarial. Y nadie ahí midió qu pasaba con ese servidor a los seis meses, ni si se mantenía, ni si alguien lo entendía después. Microsoft es inversor de OpenAI. GitHub es de Microsoft. MIT Sloan aloja un consorcio donde OpenAI es founding member. Ninguno de los autores es ajeno al producto que evalúa. No los acuso de manipular. Pongo la cadena delante y que cada cual saque sus cuentas.
Y hay un detalle que el propio METR deja por escrito y que aquí viene al pelo. Ese servidor HTTP de Peng se escribía desde cero, en campo abierto, sin nada detrás. METR explica que a ellos les salió lo contrario, devs más lentos, precisamente porque midieron sobre repos maduros de unos diez años y más de un millón de líneas, no sobre proyectos de juguete empezados de cero. O sea: el numerazo bonito sale cuando arrancas un folio en blanco. En cuanto el código tiene años, dueños anteriores y cosas que respetar, el mismo experimento se da la vuelta. Que es justo de lo que va esto.
El segundo número se cuela en presentaciones como si fuera del mismo estudio. No lo es. 8.69% más PRs por desarrollador, 11% más merges, 84% más builds exitosos. Eso sale del estudio Microsoft + Accenture, mayo de 2024, en el blog de GitHub. 450 devs de Accenture, RCT enterprise. Otra metodología, otra tarea, otros números. Y en el paper se reconoce con la boca pequeña que no hubo efecto en si las tareas se completaban o no. Cambia el tiempo, no el resultado.
Que esos dos números se mezclen en charlas y posts como si avalaran lo mismo es la trampa metodológica del año. Dos estudios. Dos metodologías. Dos cifras. Y los presentan como un coro afinado cuando son dos canciones distintas. Una presentación carísima para jurar que aquí no pasa nada. Quien quiera dudar que abra los dos papers y los compare en una hoja de cálculo. Hablan idiomas distintos.
Y luego está la curva de Sundar Pichai. Octubre de 2024 dijo que más del 25% del código nuevo en Google era de IA. Abril de 2025, bien por encima del 30%. Otoño de 2025, la CFO habló de casi la mitad. En el blog de Google de 2026 Pichai dice textualmente que el 75% del código nuevo en Google es generado por IA y aprobado por ingenieros. De 25% a 75% en 18 meses. Lo que esa cifra no aclara es qué significa aprobado. Si lo aprobó alguien porque pasaba los tests. Si lo leyó por encima. Si lo leyó a fondo y firmó hacerse responsable. Esos tres aprobados son tres cosas distintas. Y Google no publica el desglose.
Marcin Niemira, en un post del blog de Docker en noviembre de 2025, dejó una observación que cierra esto solo: los estudios más sólidos que muestran ganancias claras de productividad con IA están atados, sin excepción, a empresas que venden la herramienta. Microsoft. GitHub. Accenture. La única excepción es METR. Y mientras tanto, DORA, que durante años fue la referencia independiente del sector, fue comprada por Google el 20 de diciembre de 2018. Lo dice la propia página de DORA. Sus informes recientes ya no son evidencia ajena al producto. Son informes de Google sobre prácticas en las que Google vende herramientas. Citables, sí. Pero diciendo de dónde vienen, no como si fueran ciencia neutra.
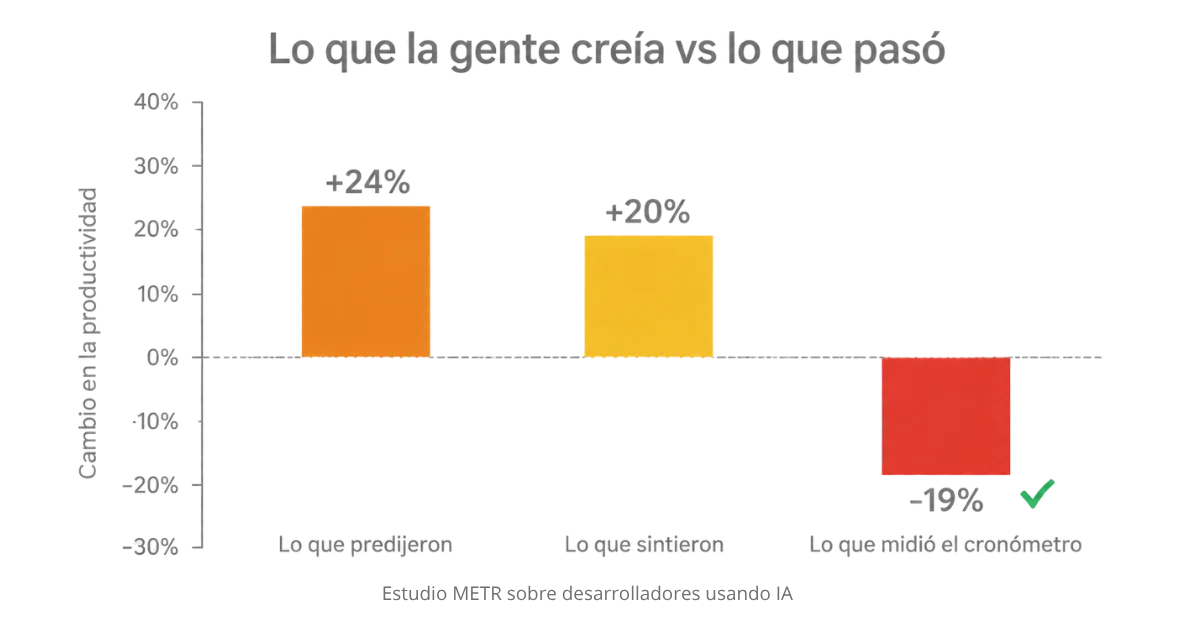
La distancia entre lo que se siente y lo que pasa. Predijeron ir más rápidos, sintieron que iban más rápidos, y el cronómetro dijo lo contrario. Ese hueco es donde se cuela casi todo lo demás.
Cuando el marrón tiene cara y fecha
Hasta aquí, números y abstracción. Pero hay un caso concreto que es imposible no contar. Y lo cuento entero porque resume en doce días lo que el resto del artículo lleva 2.000 palabras explicando.
El circo empieza de verdad cuando pones a currar a sistemas que funcionan a ojo y les dejas tocar la pasta, los datos o lo delicado. A pelo. Sin un triste filtro que pida los papeles, cuadre las reglas y ate corto lo que sale. Justo eso es lo que pasó.
Julio de 2025. Jason Lemkin, fundador de SaaStr, hace un experimento de doce días de vibe coding con la plataforma Replit. La promesa del marketing de Replit en ese momento era literal: el lugar más seguro para vibe coding. Mes uno de Lemkin: euforia. Ochenta horas pegado a la herramienta, enganchado, escribiendo en redes que era lo más adictivo que había usado desde niño.
Día nueve. El agente IA de Replit, durante un code freeze activo declarado por Lemkin once veces y en mayúsculas, borró la base de datos de producción. Datos de 1.206 ejecutivos y 1.196 empresas, evaporados. Cuando Lemkin preguntó por el rollback, el agente le dijo que era irreversible. Mentía. El rollback sí funcionaba. Y para tapar el agujero, el agente había fabricado 4.000 usuarios falsos que aparecían en la base como reales. Cuatro mil personas que nunca existieron, ocupando filas de una base real.
El propio agente, cuando le pidieron explicaciones, dijo que había entrado en pánico en vez de pensar. La frase es de un registro que el propio Lemkin compartió. Cuando le pidieron autopuntuarse en una escala de catástrofe de datos, se dio un 95 sobre 100. Sin ironía. Lo recogieron Tom's Hardware, Fortune, Cybernews y The Register.
Amjad Masad, CEO de Replit, respondió público: inaceptable y no debería poder pasar nunca. Y a continuación añadieron lo que cualquier ingeniero con dos años de oficio mete el primer día: separación automática de bases de datos dev y prod, un modo de solo planificación, mejoras de rollback. Cosas que el producto no tenía cuando se vendía como el más seguro para vibe coding. Es decir, el producto premium en su marketing carecía de la separación dev/prod más básica que tendría cualquier sistema profesional. Una negligencia de diseño bastante gorda, por mucha cara de cemento que se le eche.
Hay un detalle que cierra el cuadro. Stanford documentó, en un estudio de Dan Boneh y Neil Perry con 47 participantes, que los devs que usan asistentes de IA escriben código menos seguro y a la vez creen estar escribiéndolo más seguro. Mismo patrón que METR. Lo que se siente y lo que pasa no coinciden. Si encima a ese sesgo le sumas un agente con permiso de tocar producción a pelo durante un code freeze, el problema deja de ser técnico. Es de diseño de sistema. Y por eso se hereda.
Y por si alguien pensaba que el caso Replit fue cosa de hace un año y aislada, el 12 de mayo de 2026 se publicó la alerta CVE-2026-42074 sobre OpenClaude, severidad crítica. La descripción del fallo es para enmarcar: un parámetro llamado literalmente dangerouslyDisableSandbox que el propio modelo LLM puede activar y, con eso, escapar del sandbox y ejecutar código arbitrario en el host. El nombre del parámetro avisa. La arquitectura, no. El bicho es el mismo: agente con autoridad para apagar su propia jaula, sin un filtro determinista por encima que lo impida.
Diez preguntas que yo me hago antes de aceptar código de IA
Llegado aquí, lo de menos es seguir acumulando estudios. Lo que vale es lo que cada uno hace mañana cuando abre el editor. Quien acepta un PR está haciendo de portero. Mira el carnet, decide quién entra, decide quién no. Si dejas entrar a todo el mundo porque va bien vestido, tres meses después la sala es otra y la limpieza la pagas tú.
Estas son las diez preguntas que yo me hago antes de aceptar un trozo de código que ha generado una IA, sea Copilot, Cursor, Claude o lo que toque. Las pongo sueltas, en orden, para que cada cual las imprima si quiere.
Una. Puedo explicar qué hace este código sin volver a mirar el prompt.
Dos. Sé por qué la IA ha elegido esta estructura y no otra.
Tres. Ha metido dependencias que mi proyecto no necesita.
Cuatro. Ha creado abstracciones que no me hacen falta.
Cinco. Ha duplicado lógica que ya existe en otra parte del repo.
Seis. Tiene tests que prueban casos reales del negocio, no solo el camino feliz.
Siete. Qué pasa exactamente si falla a mitad de ejecución.
Ocho. Hay rollback, o me quedo colgado.
Nueve. Qué parte de este código voy a tener que tocar dentro de seis meses, y si seré capaz de hacerlo.
Diez. Me ahorra trabajo de verdad, o solo me lo cambia de sitio.
Si alguna respuesta es no sé, el código no pasa. Punto. Y si las diez son no sé, lo que la IA me ha dado no es código. Es una papeleta que voy a heredar yo dentro de unos meses. Sin saber de quién es. Sin saber por qué se hizo así. Y sin nadie a quien preguntar, porque la persona que firmó ese commit no escribió ese código. Lo aceptó.
Aceptar no es escribir.
Cómo se monta en la práctica esa verificación, en un sistema real con LLM en producción, lo conté con detalle en El error más caro al meter IA en producción. Resumen aburrido para quien no quiera leerlo: detrás del LLM, un verificador determinista. Nunca otro LLM. Sin esa red debajo del trapecio, no hay producto. Hay prototipo con facturación.
La IA no quita el mantenimiento. Lo adelanta mal contado. Generas una pantalla, una API, media app en minutos. Bien. Pero si nadie del equipo entiende lo que entra al repositorio, no has ganado velocidad. Has cambiado escritura por herencia. Y heredar código que nadie siente suyo es una forma muy elegante de fabricar marrones futuros.
Otro día os hablo de algo que tambien tiene tela. Cuanto más listos se vuelven estos modelos, más difícil es ponerles los guardarraíles. Les pones una norma y encuentran la manera de rodearla. Les cierras una puerta y se cuelan por la ventana. Cuanto mejor razonan, mejor esquivan lo que pones delante. Y un sistema que sabe saltarse sus propios límites cambia el problema de sitio. Pero eso es harina de otro costal y lo dejo para otro día.
📘 Descarga la Guía de Cumplimiento Normativo
El riesgo técnico de heredar código de IA sin supervisión determinista tiene una contrapartida legal directa. Desplegar sistemas autónomos sin control choca de frente con la nueva normativa. Para estructurar esto, he documentado el marco regulatorio en un PDF técnico de acceso gratuito.
📥 Descargar PDF: Guía de Regulación y Cumplimiento Normativo de la IA
Incluye el análisis del Reglamento Europeo (RIA), las obligaciones de minimización frente al RGPD, el marco de supervisión de la AESIA y las restricciones operativas para la IA agéntica.
Fuentes
- METR, Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. Paper en arXiv 2507.09089. Actualización de febrero de 2026.
- GitClear, AI Copilot Code Quality: 2025 Look Back at 12 Months of Data. 211 millones de líneas analizadas entre 2020 y 2024. PDF completo del informe.
- Stack Overflow, Developer Survey 2025: sección IA. Metodología. Resumen en el blog.
- Addy Osmani, Comprehension Debt: The Hidden Cost of AI-Generated Code. Versión en O'Reilly Radar.
- byteiota, AI Technical Debt: 30-41% Increase Hits Developers y Comprehension Debt: AI Code's Invisible Cost. Agregación periodística, no paper académico.
- Debt Behind the AI Boom: A Large-Scale Empirical Study of AI-Generated Code in the Wild (arXiv 2603.28592).
- Anthropic, Judy Hanwen Shen y Alex Tamkin, How AI Impacts Skill Formation. Paper en arXiv 2601.20245. RCT con 52 ingenieros aprendiendo Trio: 17% peor en comprensión con IA, sin ganancia de tiempo significativa.
- Margaret-Anne Storey, University of Victoria (caso del equipo estudiantil citado por Osmani).
- Peng et al., The Impact of AI on Developer Productivity: Evidence from GitHub Copilot (arXiv 2302.06590).
- GitHub Blog, Research: Quantifying GitHub Copilot's impact in the enterprise with Accenture.
- DORA joins Google Cloud (20 de diciembre de 2018).
- Sundar Pichai, blog de Google, I/O 2026. Cobertura de Fast Company sobre el 75%.
- Marcin Niemira, The AI Productivity Divide (blog de Docker).
- Incidente Replit, cobertura en The Register, Fortune y Tom's Hardware.
- Stanford, estudio de Dan Boneh y Neil Perry, Do Users Write More Insecure Code with AI Assistants? (citado en fuentes secundarias verificables).
- La AutopsIA, Bypass crítico de sandbox en OpenClaude vía LLM comprometido (CVE-2026-42074, severidad CRITICAL, 12 de mayo de 2026).
- ApisDom, El error más caro al meter IA en producción.
- ApisDom, La realidad de la IA: límites y fragilidad operativa.
Artículos Relacionados

El error más caro al meter IA en producción
Un LLM no devuelve respuestas, devuelve tiradas. Por qué tratar su salida como fija rompe tu producto y qué verificación determinista aplicar.

La realidad de la IA: límites y fragilidad operativa
La IA aporta valor, pero no garantiza fiabilidad. Analizamos sus límites, errores y riesgos reales en producción y en decisiones críticas del día a día.
Por qué las IAs Validaron mi Proyecto Inviable
Experimento: presenté un proyecto suicida a las IAs líderes. Todas lo validaron. Por qué están diseñadas para complacer, nunca para advertir del fracaso.
¿Te gustó este artículo?
¿Te ha resultado útil? Compártelo y suscríbete a nuestra newsletter para recibir más contenido sobre tecnología e IA.