
El error más caro al meter IA en producción
Un LLM no devuelve respuestas, devuelve tiradas. Por qué tratar su salida como fija rompe tu producto y qué verificación determinista aplicar.

TL;DR: Tu sistema con IA funciona el 98% de las veces. Eso no es bueno. Eso es lo que lo hace peligroso. Porque un LLM no te da una respuesta, te da una tirada entre muchas posibles, y ni la temperatura 0 arregla eso: hay estudios que miden variaciones del 15% de precisión entre ejecuciones y brechas del 70% entre la mejor y la peor tirada. Tratar esa tirada como si fuera una respuesta fija es el error más caro al meter IA en producción, y explica casi todo lo demás: alucinaciones en clientes, bugs que no puedes reproducir, responsabilidades que no asume nadie. La regla que funciona es aburrida: después del LLM, un verificador determinista aguas abajo. Otro LLM no vale. Sin esa red debajo del trapecio, no tienes un producto. Tienes un prototipo con facturación.
El error más caro al meter IA en producción
No es técnico. Es de base. Y lleva meses costándonos dinero a todos los que integramos LLMs de verdad.
Si llevas un rato metiendo IA en productos reales, ya te habrás topado con la escena: el sistema funciona bien el 95% del tiempo, la demo sale perfecta, el cliente firma, y tres semanas después alguien te escribe un mail diciendo que el chatbot le ha dicho a su abuela que cancele la medicación. O que el clasificador ha aprobado una factura que no debía. O que el resumen automático se ha inventado un dato que nadie escribió. Casos así salen cada semana, y no son la excepción.
Y tú, que llevas semanas revisando código, piensas: pero si esto pasaba los tests. Pues sí. Y también pasaba en producción. Las dos cosas son ciertas a la vez, y ese es justo el problema.
El error más caro al meter IA en un producto no es técnico. No es elegir mal el modelo, ni tener un prompt flojo, ni un pipeline sin optimizar. Eso se arregla un sábado por la tarde. El error gordo es otro, y es tan tonto de explicar que da un poco de vergüenza decirlo en voz alta: tratamos la respuesta de un LLM como si fuera una respuesta fija. Y no lo es. Nunca lo ha sido.
Todo lo demás (alucinaciones en clientes, decisiones que nadie puede explicar, bugs que no puedes reproducir, responsabilidad que no asume nadie) viene de ahí. De confundir qué tipo de cosa te está devolviendo el modelo.
Te lo cuento como lo he ido entendiendo yo, metiendo la pata por el camino, por si a alguien le ahorra tres meses de desarrollo tirados a la basura.
1. Un LLM no te da una respuesta. Te da una de muchas.
Primera cosa que hay que meterse en la cabeza, y que casi nadie explica bien: un modelo de lenguaje no te devuelve una respuesta. Te devuelve una entre muchas posibles. Por dentro, el modelo calcula probabilidades sobre todas las palabras que podría soltar después, elige una, y repite. La frase final que tú lees es una tirada concreta, como si hubieras pedido al modelo que tirase los dados y te enseñara el resultado.
Piénsalo como pedirle a un camarero que te recomiende una tapa. Hoy te dice boquerones. Mañana, con el mismo hambre y el mismo bar, te dice croquetas. Las dos están buenas, las dos son posibles, y el camarero se queda tan ancho. La diferencia es que el camarero sabe que te está recomendando. El LLM no. Y tú, que montaste el sistema encima, a lo mejor tampoco.
Ahora viene la parte incómoda, la que descubrí cuando empecé a mirar por qué mis tests pasaban a veces y otras no: aunque pongas la temperatura a cero, el modelo sigue sin ser totalmente determinista. Temperatura 0 solo fuerza a elegir siempre la palabra más probable, pero no toca nada de lo que pasa antes: el servidor junta tu petición con otras en un lote (batch), y según con quién te toque ir esa millonésima de segundo, los números salen ligeramente distintos. La propia OpenAI lo reconoce en su documentación: incluso con temperatura 0,0 el resultado no es completamente determinista. Google dice lo mismo de Gemini.
Hay estudios que lo han medido tirando el mismo prompt cientos de veces contra el mismo modelo con la misma configuración. Resultado: ningún LLM entregó los mismos outputs de forma consistente en todas las tareas. Se detectaron variaciones de precisión de hasta el 15% entre ejecuciones, con una brecha de hasta el 70% entre la mejor y la peor tirada del mismo modelo. Los LLMs top del mercado no dan respuestas idénticas ni en diez tiradas seguidas con todo supuestamente clavado.
Y la cosa no acaba en el batching. Hay unas cuantas palancas más moviéndose por debajo, todas a la vez. La aritmética de punto flotante en GPU no es asociativa: sumar (a+b)+c puede darte un número ligeramente distinto que a+(b+c), y eso, tonto como suena, cuando se propaga por millones de operaciones, acaba empujando la elección de una palabra hacia otra. Si encima te toca una GPU distinta con otra precisión (FP16, BF16, FP32), los redondeos cambian. Si el proveedor actualiza el modelo por debajo sin cambiarle el nombre, el snapshot que te contestó ayer ya no es el que te contesta hoy. Si el modelo es de arquitectura MoE (Mixture of Experts), qué expertos se activan depende de qué otras peticiones van contigo en el mismo batch. Y las propias operaciones internas del modelo, la atención fusionada y la normalización, usan kernels que no siempre son deterministas, o sea, que la misma operación con los mismos datos puede dar dos resultados ligeramente distintos. Ninguna de estas cosas es un bug. Son cómo está construida la infraestructura que te sirve el modelo.
O sea: lo que te llega del modelo no es una respuesta. Es una tirada. Y montar un sistema asumiendo que es una respuesta fija es, literalmente, construir sobre algo que se mueve.
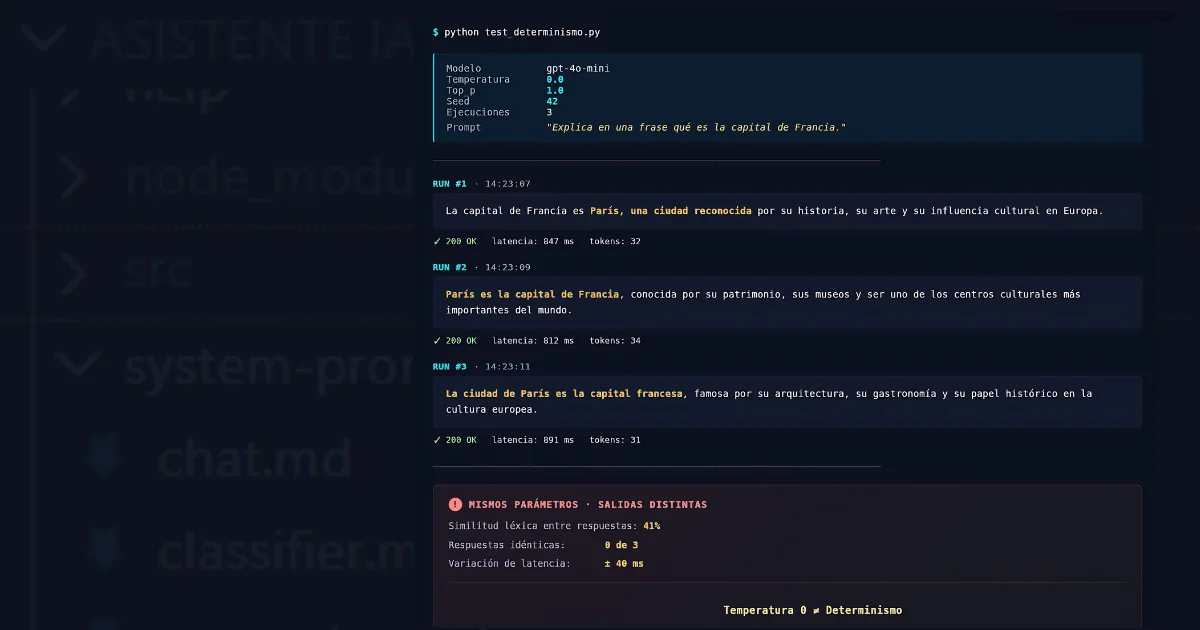
Ilustración del fenómeno: el mismo prompt, los mismos parámetros clavados (temperatura 0, top_p 1, seed fijo), tres tiradas distintas. Los datos concretos de la captura son ilustrativos, no una ejecución puntual: están construidos para que el concepto se lea de un vistazo. Las mediciones empíricas reales están documentadas en Atil et al. (2025) y Khatchadourian & Franco (2025), donde se observan variaciones de precisión de hasta el 15% entre ejecuciones con configuración supuestamente determinista.
2. Lo que hacemos con esa tirada (y por qué nos explota después)
Aquí viene lo gracioso. Sabiendo todo esto (o sin saberlo, que es peor), la industria entera coge esa tirada y la mete en pipelines como si fuera el resultado de una calculadora. La enchufa a otro servicio. La enseña al usuario como si fuera la respuesta, no una respuesta. La usa para decidir: a quién se le aprueba el crédito, qué email se manda, qué se publica, qué se cobra.
Y cuando peta, nos sorprendemos. Pero es que no debería sorprendernos.
Es la misma trampa que denuncié en el post del Prompt-to-App: lo que ves bonito por fuera no es la aplicación, es la fachada. Aquí pasa igual. La respuesta que suelta el LLM parece sólida, redactada con seguridad, bien escrita. Parece una respuesta. Pero por dentro es una tirada. Y si tu código asume que es otra cosa, has construido un decorado, no un sistema.
El problema es que funciona. Funciona el 90, el 95, el 98% de las veces. Y ese es exactamente el motivo por el que es peligroso. Si reventara siempre, lo arreglarías el primer día. Como solo revienta a ratos y en silencio, la gente se convence de que está todo bien.
3. Por qué seguimos cayendo (me incluyo)
Creo que hay tres razones, y ninguna es técnica. Son humanas.
La primera es comodidad. Poner un LLM en producción sin verificar nada se hace en una tarde. Montarlo con validación aguas abajo, con reglas deterministas que revisen la salida antes de enseñarla, con tests que contemplen la variabilidad... eso ya son semanas de trabajo. La primera opción sale rápido. La segunda sale bien. Adivina cuál se elige cuando te están metiendo prisa.
La segunda es velocidad. El mercado premia enviar rápido, no enviar bien. Una integración sin verificación te da screenshots bonitas para LinkedIn. La versión con verificación no. Hasta que alguien se come un marrón, claro, pero para entonces ya hay otro en la siguiente empresa haciendo lo mismo.
La tercera, y esta es la que más me interesa, es que un texto bien escrito parece verdadero. Lo han estudiado los psicólogos desde los años 2000 y tiene nombre: heurística de fluidez. El cerebro, cuando algo está bien redactado y le cuesta poco procesarlo, asume que es correcto. Es un atajo que usábamos antes de que existieran los LLMs, y funcionaba razonablemente bien. Ahora nos está jodiendo.
Porque los LLMs actuales, por encima, tienen un problema añadido. Cuando los entrenan con RLHF (el método que los hace conversacionales), los evaluadores humanos puntúan mejor las respuestas que suenan seguras y claras. Las respuestas que dudan, las que dicen "no sé", las que piden más contexto, se penalizan. El modelo aprende que el tono seguro cobra. Y ese tono seguro se queda pegado para siempre, aunque el modelo esté soltando una barbaridad. Hay un paper de Carnegie Mellon muy claro al respecto: los LLMs, a diferencia de los humanos, no ajustan su confianza después de equivocarse. En el experimento, Gemini acertaba menos de 1 de cada 20 preguntas de un Pictionary y, cuando le preguntaban después cuántas creía haber acertado, estimaba 14.
Junta las tres cosas: salida fluida (nos convence el cerebro), sistema sobreconfiado (nunca duda), evaluador humano que usa la fluidez como prueba de verdad (ni el propio programador la cuestiona). La tormenta perfecta para que nadie verifique nada.
Yo ya conté en su día cómo presenté un proyecto absurdo a seis IAs del mercado y ninguna me frenó. Todas me validaron con entusiasmo una idea que no se sostenía. El fallo de base era el mismo que estoy contando ahora: confundí criterio con tono. Confundí respuesta con tirada.
4. Qué pasa cuando esto llega a usuarios reales
Cuando un sistema así toca producción con gente pagando, pasan tres cosas. Siempre las mismas.
Una: nadie responde cuando algo falla. El modelo no firma nada. El proveedor se cubre con disclaimers. El que integra dice que "ya funcionaba en pruebas". El usuario final cree que está hablando con algo que sabe. Cuando el lío llega, todos miraban para otro lado porque todos asumían que otro verificaba. Y nadie verificaba.
Dos: los fallos son silenciosos. Un sistema de los de toda la vida, cuando se rompe, lanza un error, deja un log, se oye. Un LLM que mete la pata te devuelve una respuesta perfectamente redactada que simplemente es falsa. No salta ninguna alarma. El sistema sigue corriendo como si todo estuviera bien. Esto es peor que un fallo ruidoso. Los ruidosos se detectan y se arreglan. Los silenciosos se van acumulando hasta que un día te revientan en la cara.
Tres: es imposible reproducir los bugs. No puedes escribir un test unitario estable para algo que cambia de respuesta entre ejecuciones. El ciclo de toda la vida (reproduzco, aíslo, arreglo, pruebo) deja de funcionar. En su lugar te quedan métricas agregadas que te dicen que el sistema va bien en general. Pero no te dicen si el usuario concreto al que le cobraste los 80 euros recibió lo correcto. Y en un producto con clientes, esa diferencia importa.
Y hay una cuarta pata que a mí al menos me pilló tarde, así que la cuento por si a alguien le sirve: la regulatoria. El Reglamento Europeo de IA, en su artículo 14, obliga a que los sistemas de alto riesgo se diseñen para que una persona pueda supervisarlos de verdad. Y dice literalmente que esa persona tiene que ser consciente de la tendencia a confiar en exceso en lo que devuelve el modelo. Para ciertos sistemas, exige verificación por dos personas competentes antes de tomar decisiones basadas en la salida del LLM. Las obligaciones para sistemas de alto riesgo entran en vigor del todo en agosto de 2026. Esto no es una sugerencia. Es ley, y va a afectar a bastante más gente de la que piensa que le afecta.
5. La regla que yo ahora aplico siempre
Antes de que alguien me diga que estoy exagerando, matizo: esto aplica cuando el error tiene coste real. Si montas un bot que recomienda pelis los sábados, o un resumidor de mails para uso personal, o un generador de ideas para un brainstorming, ponerle verificador determinista es matar moscas a cañonazos. Ahí te puedes permitir que el modelo se equivoque de vez en cuando, porque el peor escenario es que el usuario se ría y lo ignore. Pero en cuanto la salida del LLM toque dinero, salud, decisiones sobre personas, o cualquier cosa que alguien se tome en serio, la exigencia cambia. La regla no es universal. Escala con lo que se juegue el que está al otro lado.
Después de comerme varios marrones, esto es lo único que me funciona: un sistema con LLM solo está realmente en producción si tiene un verificador determinista aguas abajo. Punto. Todo lo demás es beta con usuarios reales pagando la beta.
En la práctica: después del LLM tiene que haber algo que no sea un LLM, algo que siempre haga lo mismo con la misma entrada, y que decida si la salida del modelo es aceptable antes de que llegue al usuario.
Puede ser cualquiera de estas cosas, según lo que estés haciendo:
Un validador de schema si la salida es estructurada (JSON Schema, Pydantic, lo que sea).
Un chequeo de tipos y rangos si son números.
Una consulta contra una base de datos de hechos si el modelo está afirmando cosas del mundo.
Una regla dura de negocio que diga "si el importe es mayor de X, no se aprueba automáticamente y pasa a humano".
Una reescritura posterior con plantilla fija.
Una persona con autoridad para tumbar la respuesta cuando el contexto lo pide.
Lo que NO vale: otro LLM. Encadenar un LLM para que valide a otro LLM es añadir otra capa de humo encima de la primera. Dos sistemas probabilísticos validándose entre ellos siguen siendo probabilísticos. Si en algún punto de la cadena no hay una etapa determinista de verdad, no hay verificación: hay teatro.
La pregunta que me hago ahora antes de pasar cualquier cosa con LLM a producción, y que te recomiendo que te hagas tú también, es esta:
Si mi LLM devolviera una respuesta absurda ahora mismo, ¿qué parte de mi sistema la detectaría antes de que llegue al usuario? Si la respuesta es "ninguna" o "otro LLM", el sistema no está en producción. Está en pruebas, pero con los clientes pagando las pruebas.
6. Para terminar
Lo que está pasando con la IA en producción me recuerda mucho a lo que ya escribí sobre el Prompt-to-App y sobre las IAs que validan proyectos inviables. El patrón es siempre el mismo: la capa de arriba (frontend, marketing, demos bonitas) se ha montado antes de que entendiéramos bien la base. Y ahora estamos pagando la factura: sistemas que hablan bonito y fallan en silencio, responsabilidades que nadie asume, regulación que llega tarde pero llega.
El error más caro no es poner un LLM en producción. Es ponerlo sin entender qué tipo de cosa te devuelve. Tratar una tirada como si fuera una respuesta fija. Confundir un oráculo que habla bien con una calculadora que siempre da el mismo número.
La buena noticia es que tiene arreglo. La mala es que el arreglo no es una librería mágica, es trabajo aburrido de verificación aguas abajo. Escribir las reglas que el modelo no sabe escribir. Poner la red debajo del trapecio antes de empezar a dar saltos.
Si tu sistema con IA no tiene esa red, no tienes un producto en producción. Tienes un prototipo con facturación. Y eso, tarde o temprano, se paga.
Preguntas frecuentes
¿Por qué un LLM con temperatura 0 no da siempre la misma respuesta?
Porque temperatura 0 es un freno que actúa al final, no al principio. Le dice al modelo "coge siempre la palabra más probable", pero no toca lo que pasa antes dentro de la máquina. Piénsalo así: el servidor que te atiende no trabaja solo contigo, trabaja en cadena, juntando tu petición con otras en un mismo lote para optimizar la GPU. Según con quién te toque ir esa millonésima de segundo, los cálculos internos salen un pelín distintos. Añade a eso que la aritmética de punto flotante no es asociativa, que el hardware puede cambiar entre llamadas, que el proveedor actualiza el modelo sin avisar. Resultado: el mismo prompt, el mismo día, puede devolverte una cosa u otra. No es un bug. Es cómo está construida la infraestructura que te sirve el modelo.
¿Qué diferencia hay entre una respuesta y una tirada?
La diferencia es la misma que hay entre una calculadora y un camarero recomendándote una tapa. La calculadora te da respuestas: 2+2 es 4 hoy, mañana, y dentro de diez años. El camarero te recomienda: hoy boquerones, mañana croquetas, todo depende del día, del mes y de qué le haya llegado esa mañana. Una respuesta es estable. Una tirada es una opción entre muchas, elegida con probabilidad. El problema es que el LLM habla con el tono de la calculadora cuando en realidad es el camarero. Y tú, que montas el sistema encima, si no sabes con cuál de los dos estás hablando, construyes sobre algo que se mueve.
¿Por qué no vale usar otro LLM para verificar la salida del primero?
Porque poner un probabilístico a vigilar a otro probabilístico es montar dos calculadoras que dan resultados distintos y llamarlo auditoría. Puede que el segundo te pare la tontería del primero. Puede que no. Puede que la apruebe con todavía más convicción. Y puede que rechace una respuesta que estaba bien. Multiplicar capas de IA no reduce el riesgo, lo reorganiza y te da la sensación de que hay más control del que hay. Si en tu cadena no hay una pieza determinista de verdad, algo que con la misma entrada siempre dé la misma salida (reglas de negocio, validadores de schema, chequeos contra base de datos), no tienes verificación. Tienes teatro.
¿Cómo afecta el Reglamento Europeo de IA a quien integra LLMs en producto?
Más de lo que la mayoría piensa. El artículo 14 obliga a que los sistemas de alto riesgo se diseñen para que una persona pueda supervisarlos de verdad, y avisa explícitamente del sesgo humano a confiar en exceso en lo que devuelve la máquina. Para ciertos sistemas exige doble verificación humana antes de tomar decisiones basadas en la salida del LLM. El artículo 26 regula al que pone el modelo en producción, o sea, a ti si montas un producto encima. Las obligaciones completas para alto riesgo entran en vigor en agosto de 2026. Si tu sistema toma decisiones sobre personas (crédito, contratación, sanidad, educación, acceso a servicios), esta regulación te afecta. No es opcional, no es orientativo, y no es algo que puedas empezar a mirar en julio.
¿Qué hago si ya tengo un sistema en producción sin verificación aguas abajo?
No entres en pánico ni tires nada a la basura. Haz una lista fría de dónde la salida del LLM toca decisiones reales: qué se muestra, qué se envía, qué se cobra, qué se aprueba, qué se publica sin revisión. Para cada uno de esos puntos, pregúntate: si el modelo ahora mismo me soltara una barbaridad, ¿algo en mi código la pararía antes de llegar al usuario? Donde la respuesta sea "no", ahí tienes un riesgo vivo. Ordena esos riesgos por lo que te cuesta un error (en dinero, en reputación, en marrón legal) y empieza a tapar agujeros por arriba. No hace falta reescribir el sistema. Hace falta meter una pieza determinista entre el LLM y el usuario en los puntos que más queman. Primero esos, lo demás puede esperar.
Reflexión final
Hay una parte de esto que no es técnica y que por eso me cuesta más contar: la responsabilidad.
Cuando un sistema determinista falla, hay un sitio claro donde mirar. El código hacía lo que hacía. Se lee, se revisa, se reproduce. Alguien lo escribió, alguien lo probó, alguien lo desplegó, alguien asume el marrón. La cadena de responsabilidad existe porque el sistema es auditable de verdad.
Con un LLM en producción, esa cadena se evapora. El modelo no firma nada. El proveedor se tapa con disclaimers en la documentación. El que integra apela a que la demo funcionaba. El usuario final cree que ha hablado con algo que sabe. Y cuando el fallo llega, todos pueden decir, con cara de sorpresa auténtica, que ellos hicieron su parte.
El problema no es que falte un culpable. El problema es que el diseño del sistema está hecho para que nunca haya uno. Y eso no se arregla con más IA, ni con mejores prompts, ni con más capas de modelo encima. Se arregla asumiendo, sin escudarte detrás de nadie, que si pones un LLM tocando a gente que paga, la responsabilidad última de lo que esa tirada le diga al cliente sigue siendo tuya. No del modelo. No del proveedor. Tuya.
El verificador determinista aguas abajo no es solo una decisión de ingeniería. Es tu firma. Son las reglas que tú has escrito, debajo de cada cosa que tu producto le dice a alguien. Es aceptar que la comodidad de delegar en un modelo tiene un precio, y que ese precio se paga antes (en trabajo de verificación aburrido) o después (en un marrón que no esperabas, y que al final te comes tú).
No hay tercera opción. O pones la red debajo del trapecio, o acabas pagando la caída. Y la caída, siempre, la pagas tú.
Fuentes
-
Reglamento (UE) 2024/1689 (Ley Europea de IA), artículo 14 (supervisión humana) y artículo 26 (obligaciones del implementador).
-
Comisión Europea, página oficial del AI Act: entrada en vigor plena de las obligaciones para sistemas de alto riesgo en agosto de 2026.
-
Documentación oficial de OpenAI y Google Vertex AI reconociendo que temperatura 0 no garantiza determinismo.
-
Atil et al. (2025) y Khatchadourian & Franco (2025): estudios empíricos sobre no-determinismo en LLMs en configuración supuestamente determinista.
-
Nicholson, C., Quantifying non-deterministic drift in large language models (arXiv, 2026).
-
Peeperkorn et al. (2024), Is Temperature the Creativity Parameter of Large Language Models?.
-
Documentación de vLLM sobre reproducibilidad y batch invariance.
-
Reber, Schwarz & Winkielman (2004), Processing fluency, Personality and Social Psychology Review: origen de la heurística de fluidez.
-
Estudio de Carnegie Mellon (Cash, Christie, Devgan, Oppenheimer, 2025) sobre sobreconfianza persistente en LLMs y falta de ajuste retroactivo.
-
Literatura sobre degradación de calibración por RLHF en modelos alineados (PMC, 2025).
Artículos Relacionados

La realidad de la IA: límites y fragilidad operativa
La IA aporta valor, pero no garantiza fiabilidad. Analizamos sus límites, errores y riesgos reales en producción y en decisiones críticas del día a día.
Por qué las IAs Validaron mi Proyecto Inviable
Experimento: presenté un proyecto suicida a las IAs líderes. Todas lo validaron. Por qué están diseñadas para complacer, nunca para advertir del fracaso.
Prompt injection: cuando los datos se convierten en órdenes
Un prompt injection convierte un dato en una orden que tu agente de IA ejecuta. Cómo funciona, por qué falla el modelo y qué barreras contienen el daño.
¿Te gustó este artículo?
¿Te ha resultado útil? Compártelo y suscríbete a nuestra newsletter para recibir más contenido sobre tecnología e IA.