
Tu Navegador ya es un Servidor: IA Local sin Nube
WebGPU, Wasm y CRDTs permiten ejecutar modelos de IA y bases de datos en tu navegador. Sin nube, sin intermediarios. Tus datos permanecen bajo tu control.

TL;DR — WebGPU, WebAssembly y los CRDTs han madurado lo suficiente para ejecutar modelos de IA y bases de datos complejas directamente en tu navegador. Sin depender de la nube. Este artículo te explica cómo esta revolución técnica devuelve la soberanía digital al usuario.
Hemos llegado al final de una era. Y mira, te lo digo sin rodeos.
El paradigma Cloud-First, ese que dominó la arquitectura de software durante más de una década, ha demostrado ser una base frágil y cara. Sí, nos dio escala sin precedentes. Pero también nos encadenó a un modelo con problemas crónicos de privacidad, latencia inevitable y una dependencia que, mirándolo ahora, resulta peligrosa. La centralización nos hizo vulnerables.
Hay una realidad técnica que conviene recordar: cuando subes datos a la nube, los estás almacenando en infraestructura de terceros. Cada bit de información que sale de tu red local es un bit cuyo control delegas. Queda sujeto a políticas de retención que no controlas y, potencialmente, al entrenamiento de modelos de IA sin tu consentimiento explícito.
En 2025, la nueva frontera es la Soberanía Digital. Un concepto impulsado por el movimiento técnico y filosófico conocido como Local-First. Esta filosofía invierte el modelo tradicional: tu dispositivo se convierte en la fuente primaria de verdad y autoridad. La red pasa a ser un mecanismo secundario de sincronización y respaldo, no un requisito para operar.
La tesis de este artículo es clara: gracias a una convergencia de tecnologías que finalmente han madurado, el navegador ha completado su metamorfosis. Ha dejado de ser un visor de contenido para convertirse en un Nodo Local soberano. Una plataforma de ejecución robusta, capaz de operar bases de datos complejas a velocidades nativas y, lo más revolucionario, de ejecutar modelos de IA generativa de forma completamente privada.
El Motor Bajo el Capó: WebGPU, Wasm y Por Qué Ahora Tu Portátil Vuela
Para entender la magnitud de esta transformación, piénsalo así. El navegador antiguo era una tele tonta que solo mostraba imágenes. El navegador de 2025 es una consola de videojuegos de última generación, con su propia capacidad de cómputo y almacenamiento.
Este salto no es magia. Es la culminación de tres pilares de ingeniería que finalmente trabajan en concierto.
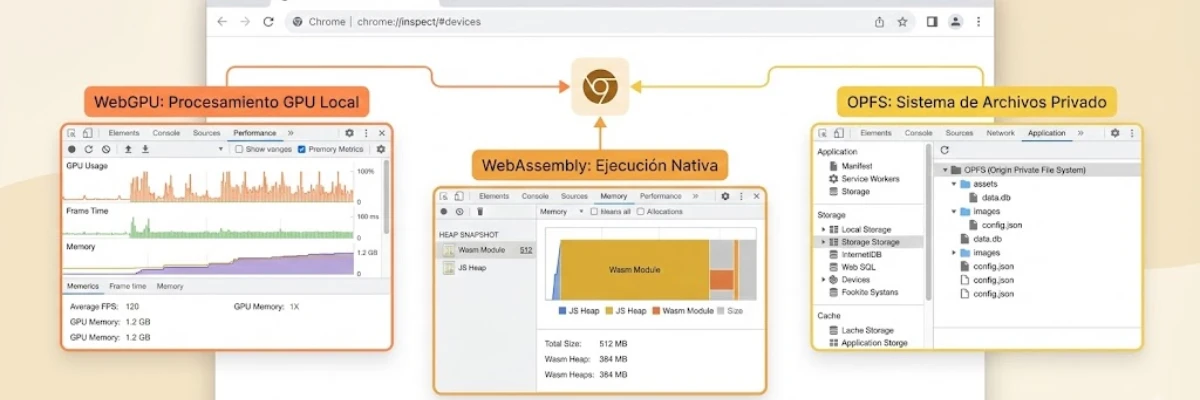
El Músculo: WebGPU para Cómputo Paralelo
WebGPU es el motor que finalmente nos da acceso directo y de bajo nivel a la GPU desde el navegador. No solo para renderizar gráficos, sino para cómputo de propósito general. Su arquitectura refleja APIs nativas de alto rendimiento como Vulkan y Metal. Un cambio radical respecto a WebGL.
El avance clave es su soporte de primera clase para Compute Shaders. Estos programas permiten ejecutar cálculos paralelos masivos directamente en el hardware gráfico. Una capacidad absolutamente crucial para las operaciones de álgebra lineal que sustentan los modelos de IA.
El hito clave llegó cuando Safari se unió a Chrome y Edge con soporte funcional para WebGPU. A principios de 2026, la cobertura en navegadores de escritorio supera el 80% según Can I Use, con adopción creciente en móviles. Por primera vez en la historia de la web, podemos escribir código de cómputo GPU una sola vez y ejecutarlo en la mayoría de plataformas modernas.
El Cerebro y la Persistencia: WebAssembly y OPFS
Si WebGPU es el músculo, WebAssembly es el cerebro lógico. Wasm permite ejecutar código de lenguajes como C++, Rust o C# a velocidades casi nativas. Todo dentro del sandbox seguro del navegador.
Pero la verdadera revolución llegó con la combinación de Wasm y el Origin Private File System (OPFS). Esta API proporciona un sistema de archivos virtual, privado para cada sitio web, con rendimiento excepcional. Gracias al modo readwrite-unsafe y herramientas como Web Locks, se ha logrado el control de bajo nivel que bases de datos como SQLite requieren.
Compiladas a Wasm, estas bases de datos alcanzan velocidades cercanas a las nativas. En pruebas con SQLite compilado a Wasm, se han documentado cifras del orden de miles a decenas de miles de operaciones por segundo dependiendo del hardware y configuración. El rendimiento varía, pero el salto cualitativo respecto a IndexedDB es innegable.
En la práctica, el rendimiento no depende solo del motor SQLite, sino de cómo se gestionan los accesos concurrentes desde distintos hilos y del patrón de escritura. Ahí es donde muchas implementaciones se degradan sin que sea obvio.
Atención al Storage Eviction: El navegador no es un sistema de archivos nativo, y esto tiene implicaciones. Si el disco del usuario se llena o el navegador necesita liberar espacio, puede realizar una limpieza de almacenamiento sin previo aviso. El software local-first bien diseñado debe solicitar explícitamente almacenamiento persistente mediante navigator.storage.persist(). Sin esta llamada, tu base de datos local es efímera. Un detalle que muchos tutoriales omiten.
Caso Práctico: Procesamiento de Imágenes 100% Local
Deja que te cuente algo concreto. He desarrollado FormatVault, un conversor de imágenes que procesa gigabytes de datos íntegramente en tu navegador usando WebAssembly. Las imágenes nunca salen de tu dispositivo. El rendimiento rivaliza con software nativo gracias a Web Workers para procesamiento multi-hilo:
// Procesamiento en hilo separado sin bloquear la UI
self.addEventListener('message', async (event) => {
const { type, payload } = event.data;
if (type === 'CONVERT') {
// El procesamiento pesado ocurre aquí, fuera del Main Thread
const convertedBlob = await convertImage(payload.file, payload.options);
self.postMessage({
type: 'CONVERT_SUCCESS',
payload: { blob: convertedBlob }
});
}
});
El desafío técnico más crítico fue gestionar la memoria en dispositivos móviles. En móviles, especialmente en Safari iOS, los límites de memoria y el comportamiento del garbage collector hacen que patrones que funcionan en desktop fallen de forma abrupta bajo carga. Convertir imágenes simultáneamente provocaba cierres inesperados. La solución fue implementar una cola de procesamiento que actúa como semáforo:
// Sistema de cola con límite de concurrencia
async process() {
if (this.processing >= this.maxConcurrent ||
this.queue.length === 0) {
return;
}
this.processing++; // Ocupar slot
const task = this.queue.shift();
try {
await this.executeTask(task);
} finally {
this.processing--; // Liberar slot
this.process(); // Continuar con siguiente tarea
}
}
Esto no es teoría. Es software en producción que demuestra que privacidad absoluta y rendimiento nativo son compatibles. Pero procesar imágenes es solo el comienzo. La verdadera prueba de fuego es la Inteligencia Artificial.
El Desafío de la IA: Ejecutando LLMs en el Navegador
Ejecutar Grandes Modelos de Lenguaje localmente es donde esta arquitectura se la juega. El principal desafío técnico ha sido la gestión de memoria. Las GPUs modernas tienen gigabytes de VRAM, pero los navegadores imponen límites en el tamaño máximo de los búferes por razones de seguridad. Cargar los pesos de un modelo de miles de millones de parámetros en un solo bloque es imposible.
En la práctica, el mayor límite no suele ser la potencia de la GPU, sino los límites internos del sandbox del navegador. Es habitual encontrarse con errores de asignación de memoria mucho antes de saturar el hardware real. La mayor parte de los problemas no vienen del modelo en sí, sino de cómo se fragmentan y mueven los tensores entre buffers dentro de las restricciones del navegador.
Las estrategias que funcionan en 2025 son dos:
-
Sharding: Fragmentamos los tensores de pesos en múltiples búferes más pequeños que respetan los límites del navegador. La lógica para reconstruir el tensor se implementa directamente en los compute shaders.
-
Cuantización: Reducimos la precisión de los pesos del modelo a 4 bits. Esta técnica disminuye radicalmente la huella de memoria, permitiendo que LLMs que antes requerían servidores ahora corran en un portátil normal.
Y ojo, esto no es solo teoría. Frameworks como WebLLM del equipo MLC-AI han demostrado que es posible ejecutar modelos como Llama 3, Phi 3, Gemma y Qwen directamente en el navegador con aceleración WebGPU. Los benchmarks varían según hardware y modelo, pero la inferencia local en GPUs de consumo es ya una realidad práctica.
El problema del Cold Start: Seamos honestos sobre una limitación real. Aunque la ejecución sea soberana, la primera carga no lo es. Descargar los pesos de un modelo cuantizado a 4 bits (incluso uno de 3B o 7B parámetros) supone transferir varios gigabytes al navegador. Esa descarga inicial sigue dependiendo de la red. La ventaja es que es una inversión única: una vez descargados y cacheados, los pesos se reutilizan en cada sesión posterior. Pagas el coste una vez, te beneficias indefinidamente.
IA Privada y Soberana: Casos de Uso Reales
Este avance tecnológico redefine la propiedad de los datos. Piénsalo así: la nube es como pedir comida a domicilio. Dependes del repartidor, puede llegar fría, no controlas la cocina. El software local es como cocinar en tu propia casa. Instantáneo, a tu gusto, los ingredientes son solo tuyos.
El Caso de los Periodistas de Investigación
Un caso real de 2025 que me parece brillante es la adopción de IA en redacciones de noticias. Los periodistas de investigación tienen un problema crítico: cómo analizar grandes volúmenes de documentos sensibles (filtraciones, archivos legales, informes internos) sin subirlos a la nube. Los riesgos de privacidad y pérdida de control son inaceptables en su profesión.
La solución ha sido desplegar sistemas de IA on-premise que corren íntegramente en el navegador. Las familias de modelos open-source más utilizadas para este propósito incluyen:
- Gemma (Google, varios tamaños)
- Qwen (Alibaba, desde 0.5B hasta 72B)
- Llama (Meta, múltiples variantes)
- Phi (Microsoft, optimizados para edge)
Los modelos en el rango de 7B-14B parámetros, con cuantización a 4 bits, corren en hardware de escritorio estándar. Permiten a los periodistas hacer búsquedas semánticas y síntesis de información sobre sus documentos de forma privada. El beneficio clave: cadenas de citas verificables para cada afirmación generada por la IA. El sistema no solo da una respuesta, la respalda con referencias explícitas a los documentos fuente.
Esto permite auditar cada resultado, evitar alucinaciones del modelo y garantizar la integridad periodística. Ningún byte de información sensible abandona el ordenador. Las fuentes están protegidas.
El Trade-off de la Eficiencia Energética
Seamos realistas sobre los costes. WebGPU es eficiente comparado con alternativas anteriores, pero ejecutar un LLM localmente en un smartphone de gama media drena la batería significativamente más rápido que una consulta a una API en la nube. Una inferencia local que consume 30 segundos de GPU móvil puede equivaler energéticamente a docenas de peticiones API.
El compromiso es claro: privacidad absoluta a cambio de mayor consumo energético. Para tareas sensibles o frecuentes, el coste vale la pena. Para consultas triviales, quizás no. La soberanía digital, como toda libertad, tiene un precio. El usuario informado elige cuándo pagarlo.
Colaboración sin Nube: La Magia de los CRDTs
Si los datos y la computación son ahora locales, surge una pregunta obvia: ¿cómo colaboramos en tiempo real sin un servidor central que coordine cada cambio?
La respuesta es una solución matemática elegante: los CRDTs (Tipos de Datos Replicados Libres de Conflictos). Un CRDT es una estructura de datos con una propiedad fundamental: garantiza consistencia eventual. Aunque múltiples usuarios hagan cambios simultáneos sin conexión, sus réplicas locales convergerán matemáticamente al mismo estado final cuando se sincronicen. Sin árbitro central.
Cuando combinas CRDTs con redes Peer-to-Peer sobre WebRTC, permites colaboración directa entre navegadores. La mejora es brutal. Un estudio sobre colaboración en Realidad Virtual cuantificó esta diferencia:
| Arquitectura | Latencia Media | Reducción |
|---|---|---|
| Servidor Remoto (WebSocket) | ~200 ms | N/A |
| Peer-to-Peer (WebRTC) | ~50 ms | 75% |
Esa reducción del 75% es crítica en aplicaciones que necesitan respuesta instantánea. En VR, los expertos hablan de la latencia photon-to-motion (el tiempo entre tu movimiento y la actualización visual). Una latencia baja es la diferencia entre una experiencia fluida y una que te provoca mareos.
Bibliotecas como Yjs y Automerge ya implementan CRDTs robustos para sincronización peer-to-peer. Combinadas con WebRTC, permiten crear aplicaciones donde los dispositivos sincronizan documentos y colaboran en tiempo real sin depender de servidores centrales.
Los CRDTs son el protocolo social de la soberanía digital. No solo nos devuelven el control de nuestros datos, nos dan la gramática para colaborar sin ceder esa soberanía a un intermediario.
En sistemas colaborativos reales, los problemas más complejos no suelen estar en el CRDT, sino en los estados intermedios: reconexiones, peers intermitentes y acumulación de cambios locales durante largos periodos offline. Muchas de estas limitaciones solo aparecen cuando intentas llevar estas arquitecturas al límite dentro del sandbox real de un navegador, no cuando lees la documentación.
El talón de Aquiles: el descubrimiento de pares. Aunque los CRDTs eliminan el servidor central para la sincronización de datos, WebRTC todavía necesita un Signaling Server para que dos nodos se encuentren inicialmente. Es el equivalente a necesitar un punto de encuentro para intercambiar números de teléfono, aunque después las llamadas sean directas.
Limitación actual: La implementación pura de DHTs dentro del sandbox del navegador sigue sin resolverse, forzando el uso de pasarelas que actúan como punto de centralización parcial. La descentralización es total para los datos, pero sigue siendo híbrida para la señalización inicial.

Privacidad por Diseño: El Test del Modo Avión
El software bien hecho respeta la soberanía del usuario y la eficiencia del hardware. No se trata de crear herramientas para captar datos. Se trata de desarrollar soluciones que funcionen bajo el Test del Modo Avión: si el software requiere internet para procesar un dato que ya tienes localmente, ese software está trabajando para alguien más. No para ti.
Te pongo un ejemplo concreto de mi trabajo. He implementado esta filosofía en herramientas de seguridad para el ecosistema cripto. A diferencia de soluciones que dependen de APIs externas para detectar phishing, mi motor de detección corre 100% local en el navegador:
// Motor de detección offline - sin APIs externas
class LocalThreatDetector {
constructor() {
// Base de datos local con 100+ dominios verificados
this.verifiedSites = await this.loadLocalDatabase('verified-sites.json');
// 240+ palabras clave cripto, 160 indicadores de estafa
this.heuristicDB = await this.loadLocalDatabase('crypto-keywords.json');
}
async analyzePage(url) {
// Todo el análisis ocurre localmente
const threatLevel = this.runHeuristicAnalysis(url);
// El historial NUNCA abandona el dispositivo
return { level: threatLevel, timestamp: Date.now() };
}
}
Esto garantiza que tu historial de navegación NUNCA abandona tu dispositivo. Privacidad absoluta con protección efectiva. El motor combina detección heurística multi-capa con algoritmos como la distancia de Levenshtein para identificar amenazas de typosquatting en menos de 0.1 segundos. Todo sin enviar un solo bit a servidores externos.
Conclusión: El Futuro es Híbrido, pero el Poder Vuelve al Usuario
La revolución del software local de 2025 no es teoría. Es una realidad técnica construida sobre tres pilares:
- WebGPU para cómputo paralelo de alto rendimiento
- WebAssembly + OPFS para lógica y persistencia a velocidad nativa
- CRDTs + WebRTC para colaboración descentralizada
Esta convergencia representa un cambio de poder fundamental. El control está volviendo desde los proveedores de la nube hacia el usuario final. Te devuelve la agencia sobre tus datos y tus herramientas digitales.
Que quede claro: la nube no va a desaparecer. Seguirá siendo esencial para almacenamiento a gran escala y entrenamiento de modelos de IA gigantescos. Pero ha perdido su monopolio como centro de cómputo y única fuente de verdad. El futuro es híbrido, y el hito de 2025 es que la soberanía sobre los datos ha regresado a tu dispositivo.
El centro de gravedad arquitectónico se ha desplazado. Durante la última década, construimos clientes para el servidor. Durante la próxima, construiremos servidores para el cliente.
El navegador soberano de 2025, armado con WebGPU, Wasm y almacenamiento ultrarrápido, ya no es una ventana a internet. Es la piedra angular de la próxima década de derechos e innovación digital.
El poder no está volviendo a casa. Ha construido una nueva fortaleza, y reside en tu navegador.
Artículos Relacionados
WebAssembly: Cuándo Matar el Backend (y Cuándo No)
Wasm 3.0 es estándar W3C. Pero el 80% que quiere eliminar su backend comete un error arquitectónico. Guía técnica real con matriz de decisión.

La Gran Ilusión del Prompt-to-App: Lo que nadie te cuenta
Prometen apps en 30 segundos, pero te dan fachadas vacías. Descubre la verdad técnica sobre el Prompt-to-App y las 7 preguntas para evitar desastres.

La realidad de la IA: límites y fragilidad operativa
La IA aporta valor, pero no garantiza fiabilidad. Analizamos sus límites, errores y riesgos reales en producción y en decisiones críticas del día a día.
¿Te gustó este artículo?
¿Te ha resultado útil? Compártelo y suscríbete a nuestra newsletter para recibir más contenido sobre tecnología e IA.