
WebAssembly: Cuándo Matar el Backend (y Cuándo No)
Wasm 3.0 es estándar W3C. Pero el 80% que quiere eliminar su backend comete un error arquitectónico. Guía técnica real con matriz de decisión.
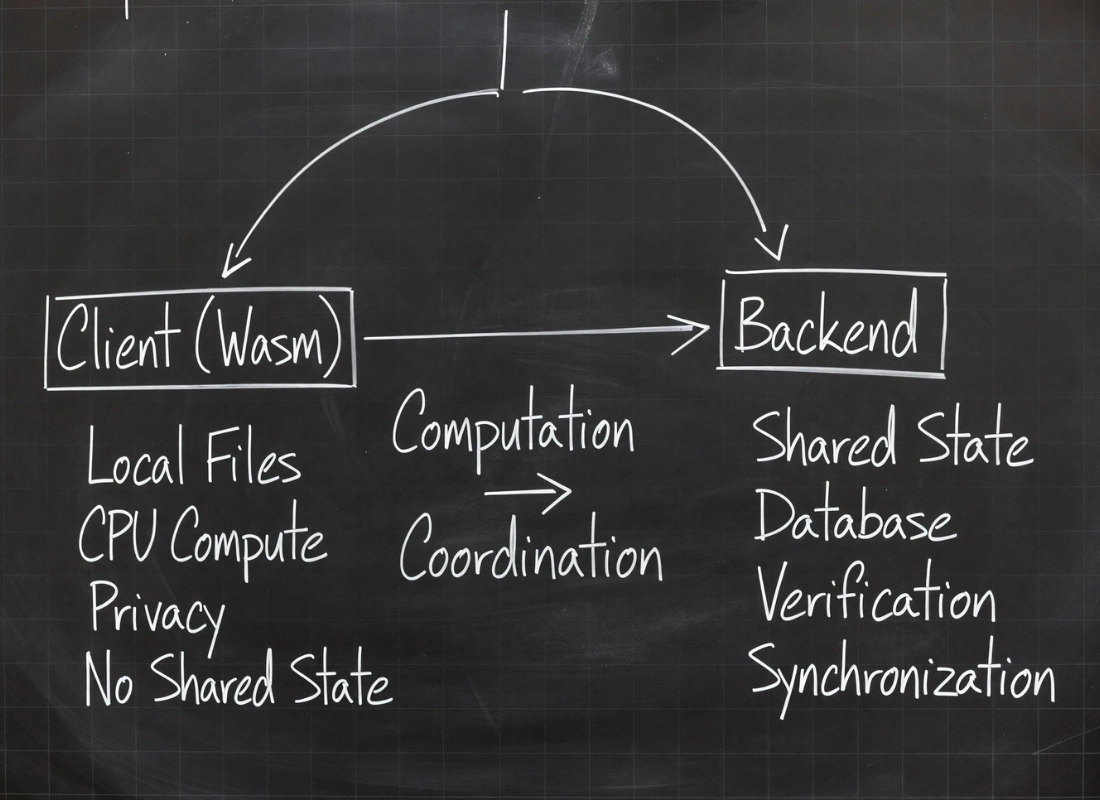
TL;DR El 80% de los equipos que quieren "matar el backend" con WebAssembly están tomando una mala decisión arquitectónica. No porque Wasm no funcione, sino porque confunden rendimiento con arquitectura. Wasm 3.0 es estándar W3C desde septiembre de 2025. Google Sheets va 2x más rápido con él. Figma carga 3x más rápido. Pero ninguno de ellos mató su backend. Este artículo te explica cuándo la eliminación del servidor es legítima, cuándo es una trampa cara, y el patrón de fracaso que se repite cuando se confunden las dos cosas.
El Artículo Anterior me Dejó una Deuda Pendiente
Si crees que WebAssembly te permite eliminar tu backend en la mayoría de los casos, estás confundiendo rendimiento con arquitectura. Esa confusión tiene consecuencias reales, y este artículo existe para nombrarlas.
En el artículo anterior hablé de cómo el navegador se ha convertido en un nodo soberano: WebGPU para cómputo paralelo, WebAssembly para velocidad nativa, OPFS para persistencia local. Mostré FormatVault procesando imágenes sin tocar ningún servidor. Mostré Brújula Security detectando phishing sin enviar un solo byte a APIs externas.
Y ahí está el problema.
Ese artículo explica qué es posible. Este explica cuándo tiene sentido hacerlo y, más importante todavía, cuándo migrar lógica al cliente con Wasm es un error de arquitectura que te va a costar caro. Porque hay una diferencia enorme entre poder hacer algo y que sea la decisión correcta.
Primero: El Estado Real de Wasm en 2026
Antes de tomar cualquier decisión arquitectónica necesitas saber dónde está realmente la tecnología hoy, no en 2021 cuando la mayoría de artículos que circulan por internet fueron escritos.
Wasm 3.0 se convirtió en estándar W3C el 17 de septiembre de 2025. No es una versión beta, no es un draft. Es el estándar vivo. Las novedades que importan para decisiones de arquitectura son concretas, y la principal es WasmGC:
Recolección de basura nativa (WasmGC) el cambio real de Wasm 3.0. Antes, si compilabas Java, Kotlin o C# a Wasm, tenías que empaquetar el recolector de basura completo del lenguaje dentro del propio binario. El resultado: binarios monstruosamente grandes que tardaban en descargarse y en compilarse. Con WasmGC, el runtime del navegador gestiona la memoria automáticamente, igual que hace con JavaScript. Esto es lo que hace que Kotlin/Wasm sea viable en producción hoy y no antes. Google Sheets migró su motor de cálculo a WasmGC y funciona el doble de rápido que en JavaScript puro.
Espacio de direcciones de 64 bits. Antes el límite era 4 GB de memoria por módulo. Ahora son 16 GB en navegadores. Esto elimina una restricción que hacía inviable Wasm para procesamiento de datos grandes.
Múltiples memorias en un solo módulo. Permite arquitecturas más complejas sin recurrir a módulos separados y facilita herramientas de static linking como wasm-merge.
El ecosistema en números reales: según el análisis de adopción enterprise publicado por ByteIota en diciembre de 2025, la presencia en sitios visitados por Chrome pasó del 3,5% al 4,5% en un año, un incremento del 28%. Cloudflare Workers y Fastly Compute@Edge procesan miles de millones de invocaciones diarias sobre Wasm. Google Sheets migró su motor de cálculo con WasmGC y va 2x más rápido. Figma compiló su motor gráfico en C++ a Wasm y consiguió 3x de mejora en tiempos de carga. Zoom usa Wasm para procesamiento de audio y video en el cliente sin depender de plugins nativos.
Cuando empresas cuyo negocio depende del rendimiento y la escala apuestan por Wasm en producción, la tecnología ya no está en fase experimental.
Pero fíjate bien: todos estos casos son Wasm en el servidor o en el edge, no en el cliente sustituyendo backends completos. Esa distinción es la columna vertebral de este artículo.
La Pregunta Correcta (Que Nadie se Hace)
Cuando la gente lee sobre Wasm ejecutándose en el navegador a velocidad nativa, la conclusión que sacan es: Perfecto, elimino el servidor. Esa conclusión es prematura y a menudo incorrecta.
La pregunta correcta no es ¿puede Wasm hacer esto en el cliente? La respuesta a esa pregunta casi siempre es sí. La pregunta correcta es si la lógica que quieres mover al cliente cumple estas condiciones:
- Es computación pura sobre datos que el usuario ya tiene localmente.
- No requiere estado compartido entre múltiples usuarios simultáneos.
- El dataset no crece indefinidamente más allá de lo que el dispositivo puede gestionar.
- La privacidad del usuario se beneficia de que el proceso ocurra localmente.
- El resultado no tiene que ser verificable por un tercero (auditoría, compliance, antifraude).
Si la respuesta a todas es sí, Wasm en el cliente no solo es viable: es la arquitectura correcta. Si alguna es no, necesitas un backend, y ninguna cantidad de Wasm va a cambiar eso.
Cuándo Wasm en el Cliente Mata el Backend de Forma Legítima
Procesamiento de archivos sin límite de tamaño
Es el caso más limpio. El usuario tiene un archivo en su máquina. Quiere convertirlo, firmarlo, dividirlo, protegerlo. ¿Para qué enviar ese archivo a un servidor, esperar la red, y recibirlo de vuelta?
La comparación con la calle: es la diferencia entre llevar tu coche al taller para que te cambien el aceite (backend) versus tener el kit y hacerlo tú mismo en el garaje (Wasm local). Si tienes el conocimiento y las herramientas, el resultado es idéntico y más rápido. Si no, necesitas al mecánico.
Dos ejemplos de producción que ilustran el patrón:
FormatVault procesa imágenes localmente con WebAssembly. El archivo nunca sale del dispositivo. Sin límite de tamaño impuesto por una API externa, sin costes de transferencia, sin latencia de red.
DoctVault lleva el mismo principio a documentos PDF, que es un caso más exigente técnicamente. Firmar un PDF, unir varios, dividirlo por páginas, protegerlo con contraseña AES-256, reordenar páginas con drag & drop — todo ocurre en el navegador usando pdf-lib, pdfjs-dist y Web Workers para no bloquear la interfaz durante operaciones pesadas. El documento nunca abandona el dispositivo del usuario. Eso no es un argumento de marketing: es una consecuencia directa de que no hay ningún servidor al que enviarlo.
Lo que hace interesante a DoctVault como ejemplo arquitectónico no es solo que funcione localmente, sino la complejidad de las operaciones que soporta: firma táctil con canvas, posicionamiento visual en coordenadas reales del documento, batching dinámico según si el dispositivo es móvil o desktop, progreso en tiempo real vía mensajes del Worker. Todo eso sin backend.
// pdfProcessor.worker.js — operación real con progreso en tiempo real
postMessage({ type: 'PROGRESS', value: progress })
const mergedPdf = await mergePDFs(files, {
onProgress: (p) => sendProgress(p)
})
postMessage({ type: 'SUCCESS', blob: mergedPdf })
Si alguien te dice que este tipo de operaciones requieren necesariamente un servidor, no sabe qué es posible con las APIs actuales del navegador.
Otros casos donde aplica el mismo principio: edición de video en el navegador, compresión y cifrado de archivos antes de subirlos, análisis de logs locales, generación de documentos a partir de datos del usuario.
Detección y análisis que requiere privacidad absoluta
Si la lógica de negocio requiere que los datos del usuario nunca salgan del dispositivo, Wasm en el cliente es la única arquitectura honesta. Un backend siempre implica que los datos viajan a tu infraestructura. Puedes poner las políticas de privacidad que quieras en el texto legal, pero el dato sale del dispositivo.
Esto no es solo un argumento moral. Es un argumento técnico ante reguladores. GDPR artículo 25 habla de privacidad por diseño como principio arquitectónico. Una aplicación que procesa datos locales sin transmitirlos tiene una postura de cumplimiento radicalmente más sencilla de defender.
Inferencia de modelos de IA pequeños o medianos
Con WebGPU y librerías como Transformers.js de Hugging Face ya es posible ejecutar inferencia de modelos en el navegador para casos concretos: clasificación de texto, detección de objetos en imágenes, embeddings semánticos para búsqueda local. No estamos hablando de GPT-4, estamos hablando de modelos de 50 MB a 500 MB que hacen tareas específicas con precisión suficiente para producción.
Si tu aplicación necesita estos modelos y la privacidad del usuario importa, ejecutarlos localmente elimina el backend de inferencia completamente. El coste en infraestructura de servir inferencia a escala es brutal. Wasm + WebGPU local lo elimina del todo.
Cuándo Wasm NO Puede Matar el Backend
Estado compartido entre usuarios
Wasm en el cliente es extraordinario para computación local. Es absolutamente inútil para coordinar múltiples usuarios simultáneos. Si tu aplicación necesita que el usuario A y el usuario B vean el mismo estado actualizado en tiempo real, necesitas un mecanismo de sincronización. Ese mecanismo es un servidor, o una red peer-to-peer con señalización (que sigue requiriendo infraestructura).
La comparación con la calle: Wasm en el cliente es como tener una calculadora potente en tu bolsillo. Perfecta para hacer tus propios cálculos. Inútil para sincronizar los libros de contabilidad de toda la empresa en tiempo real.
Los CRDTs ayudan con la sincronización eventual sin servidor central para los datos, pero incluso WebRTC necesita un servidor de señalización para el descubrimiento inicial de pares. La descentralización total de datos es real. La descentralización total de infraestructura sigue siendo parcialmente híbrida en la práctica.
Datasets que crecen sin límite controlado
OPFS (Origin Private File System) es rápido, mucho más que IndexedDB. Pero el navegador no es un sistema de archivos nativo. Si el disco del usuario se llena, el browser puede limpiar el almacenamiento de tu aplicación sin previo aviso a menos que hayas llamado explícitamente a navigator.storage.persist().
Más importante: si tu aplicación necesita gestionar gigabytes que crecen de forma continua, correlacionar datos de múltiples usuarios, o ejecutar queries complejas sobre datasets históricos grandes, el cliente no es el lugar correcto. SQLite compilado a Wasm alcanza miles de operaciones por segundo en hardware moderno, pero un servidor PostgreSQL bien configurado maneja órdenes de magnitud más con menos fricción operacional.
Lógica que requiere verificación externa
Antifraude, compliance financiero, auditorías regulatorias, control de acceso crítico. Si el resultado de una operación tiene que ser verificable por alguien que no es el usuario, esa operación no puede vivir exclusivamente en el cliente. Un usuario con suficiente conocimiento técnico puede modificar el código Wasm en su navegador. El sandbox de Wasm protege al usuario de código malicioso, no protege a tu sistema de un usuario malicioso.
Es la diferencia entre privacidad (proteger los datos del usuario del exterior) y integridad (garantizar que las operaciones son correctas ante terceros). Wasm local es excelente para lo primero. Para lo segundo necesitas un servidor de confianza.
Acceso a recursos del sistema operativo que el browser no expone
Wasm en el navegador está sandboxed. No puede acceder directamente al sistema de archivos nativo del usuario, no puede abrir sockets TCP arbitrarios, no puede ejecutar procesos del sistema. Para todo eso necesitas WASI (Wasm fuera del browser) o un backend tradicional.
El Anti-Patrón que se Repite: Matar el Backend Antes de Entender el Sistema
No es un caso aislado. Es un patrón que aparece repetidamente cuando equipos descubren el rendimiento de WebAssembly en el cliente y concluyen que pueden eliminar el backend completo. La secuencia suele seguir el mismo recorrido.
Fase 1 Descubrimiento técnico y entusiasmo
El equipo ve ejemplos reales de rendimiento: procesamiento local extremadamente rápido, eliminación de latencia de red, reducción de costes de infraestructura. La conclusión inicial parece lógica: si todo puede ejecutarse en el cliente, el servidor deja de ser necesario.
Aquí ocurre la primera confusión: rendimiento y arquitectura no son la misma cosa. Que algo pueda ejecutarse localmente no significa que deba convertirse en la fuente de verdad del sistema.
Fase 2 Migración prematura de lógica crítica
Se empieza trasladando al cliente validación de datos, lógica de negocio, persistencia local, cálculos que antes vivían en el backend. Durante esta fase, todo parece funcionar. Los tests pasan. La experiencia individual del usuario mejora. Pero el sistema todavía no está bajo presión real.
Fase 3 Aparición de problemas estructurales
Cuando el producto crece, emergen limitaciones que no son de rendimiento, sino de arquitectura: necesidad de estado compartido entre usuarios, inconsistencias entre dispositivos del mismo usuario, imposibilidad de verificar resultados desde un sistema externo, conflictos de sincronización, lógica crítica ejecutándose en entornos no confiables.
El problema no es Wasm. El problema es haber confundido computación local con coordinación distribuida.
Fase 4 Reintroducción inevitable de infraestructura
La mayoría de sistemas que recorren este camino terminan reintroduciendo un backend parcial para sincronización, verificación, control de acceso, agregación de datos y auditoría. El resultado final suele ser una arquitectura híbrida: computación intensiva local, coordinación centralizada.
Irónicamente, esa suele ser la arquitectura correcta desde el principio.
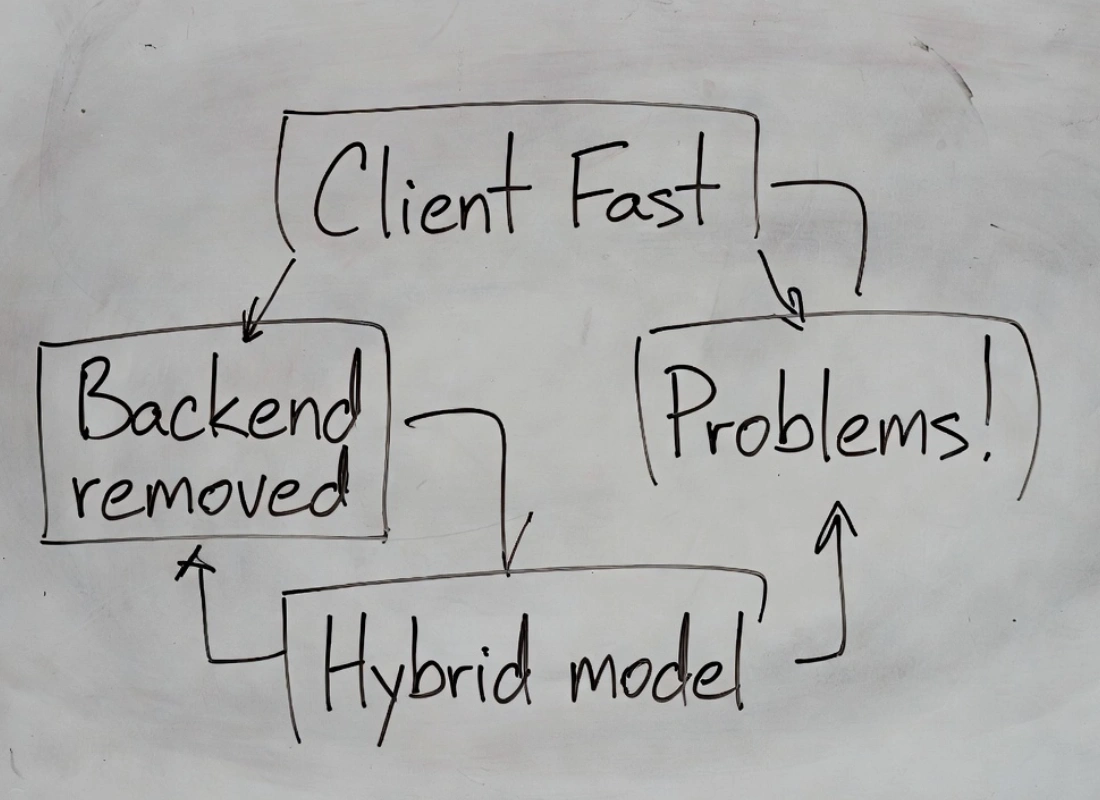 El ciclo se repite. El modelo híbrido no es el plan B. Suele ser el diseño correcto desde el principio.
El ciclo se repite. El modelo híbrido no es el plan B. Suele ser el diseño correcto desde el principio.
La lección
WebAssembly en el cliente no elimina la necesidad de arquitectura distribuida. Solo elimina la necesidad de ejecutar computación innecesaria en servidores. El error recurrente no es usar Wasm. Es intentar convertir el cliente en la fuente de verdad de sistemas que requieren consenso, coordinación o verificabilidad externa.
Los Límites Técnicos Reales que los Tutoriales Omiten
El problema de SharedArrayBuffer y los headers COOP/COEP
Para conseguir verdadero multi-threading en Wasm (múltiples Workers compartiendo memoria), necesitas SharedArrayBuffer. Y para usar SharedArrayBuffer en un navegador moderno, tu servidor tiene que enviar dos headers HTTP específicos en cada respuesta:
Cross-Origin-Opener-Policy: same-origin
Cross-Origin-Embedder-Policy: require-corp
Esto activa el estado de cross-origin isolation, que el browser requiere para mitigar ataques de tipo Spectre (vulnerabilidades de canal lateral que permiten leer memoria de otros procesos). El problema es que estos headers rompen la carga de recursos cross-origin que no hayan optado explícitamente por ser embebidos. Si tu app usa Google Maps, scripts de analytics, iframes de terceros, o cualquier recurso externo que no sirva los headers CORP adecuados, tienes un conflicto directo. MDN documenta exactamente este comportamiento y sus implicaciones.
La consecuencia práctica: muchas aplicaciones que necesitan threading real en Wasm tienen que elegir entre el multi-threading o la integración con servicios de terceros. No puedes tener ambos fácilmente sin trabajo adicional significativo. Esto es un límite de producción real, no teórico.
La alternativa cuando no puedes servir esos headers es usar Web Workers con paso de mensajes mediante postMessage y Structured Clone. Funciona sin COOP/COEP, pero introduce una copia de los datos en cada cruce entre hilos. Para buffers grandes (imágenes, PDFs pesados) ese coste de copia puede ser significativo. La solución es usar Transferable objects (pasar la propiedad del ArrayBuffer en lugar de copiarlo), aunque esto implica que el hilo origen pierde acceso al buffer una vez transferido. No es un bloqueante, pero sí una decisión de diseño que hay que tomar conscientemente.
El cold start no es cero en el cliente
En el servidor o en el edge, Wasm tiene cold starts sub-milisegundo. Pero en el cliente, la historia es diferente.
Un módulo Wasm generado desde Rust sin optimización de tamaño supera fácilmente los 300 KB sin comprimir. Con aplicaciones más complejas, algunos módulos llegan a varios MB. La primera carga, el browser tiene que descargar ese binario, validarlo, y compilarlo a código nativo. Esto no es instantáneo.
La mitigación es streaming compilation: el browser puede empezar a compilar mientras descarga usando WebAssembly.instantiateStreaming(). Pero si el módulo es grande y el usuario está en una conexión lenta, el tiempo hasta que Wasm está listo puede ser de varios segundos. Si no has diseñado una experiencia de carga para ese periodo, el usuario ve una pantalla congelada.
La buena noticia: el browser cachea el módulo compilado. La segunda carga es prácticamente instantánea. Pero la primera experiencia importa, especialmente para usuarios nuevos.
La estrategia de mitigación real es dividir el módulo Wasm en chunks lazy-loaded: solo cargar la parte crítica en el arranque y el resto bajo demanda. Leptos, el framework Rust/Wasm, implementó binary splitting en verano de 2025 exactamente por esta razón, con soporte para macros #[lazy] que marcan funciones para carga diferida.
El overhead de la frontera Wasm-JavaScript
Wasm no puede tocar el DOM directamente. Cada vez que tu módulo Wasm necesita actualizar la interfaz, tiene que cruzar la frontera hacia JavaScript. Cada cruce tiene un coste de serialización y deserialización.
Para cómputo puro sobre datos (la imagen entera como ArrayBuffer, el dataset completo en memoria Wasm), este overhead es despreciable. Pero si tu código Wasm está constantemente enviando pequeños fragmentos de datos hacia JS para actualizar la UI, el overhead acumulado puede anular por completo la ventaja de velocidad.
La regla práctica: diseña la API entre Wasm y JS para minimizar cruces. Una sola llamada que devuelve un resultado grande es mucho mejor que muchas llamadas pequeñas. Es el mismo principio que optimizar queries SQL: N+1 queries matan el rendimiento aunque cada query individual sea rápida.
El infierno del debugging
Chrome DevTools ha mejorado el soporte para debugging de Wasm, pero la experiencia todavía no es comparable a JavaScript. Los stack traces en producción de módulos Wasm sin source maps son crípticos. Los memory leaks son difíciles de detectar.
Si tu equipo no tiene experiencia con el lenguaje fuente que compila a Wasm (Rust, C++, C), el ciclo de debug en producción puede ser significativamente más largo que con JavaScript. Esto no es un argumento para no usar Wasm. Es un argumento para planificar el debugging como parte del diseño, no como un afterthought.
La Matriz de Decisión: Úsala Antes de Escribir Una Línea
| Escenario | Wasm Cliente | Backend / Edge |
|---|---|---|
| Cómputo puro, datos locales | Correcto | Evitar |
| Datos que no deben salir del dispositivo | Correcto | Evitar |
| Estado compartido entre usuarios | Evitar | Correcto |
| Dataset que crece sin límite | Evitar | Correcto |
| Resultado verificable externamente | Evitar | Correcto |
| Cold start en edge / serverless | Depende | Correcto |
| Inferencia IA privada (< 500 MB) | Correcto | Depende |
| Acceso a recursos del SO nativo | Evitar | Correcto |
| Antifraude / auditoría crítica | Evitar | Correcto |
| Multi-threading sin restricciones | Depende | Correcto |
Wasm Más Allá del Browser: Lo que Cambia la Ecuación del Backend
La discusión cliente-vs-backend tiene una tercera opción que reencuadra todo y que muchos desarrolladores web todavía no han procesado: WASI.
WASI (WebAssembly System Interface) lleva Wasm fuera del browser. Con Wasmtime, Wasmer, o el runtime integrado en Docker, puedes ejecutar módulos Wasm en servidores y en el edge con las mismas garantías de aislamiento y portabilidad que en el cliente. La consecuencia arquitectónica es directa: el mismo módulo puede correr en Cloudflare Workers, en tu servidor propio, o en el navegador del usuario. La decisión de dónde ejecutar deja de ser una decisión de reescritura y pasa a ser una decisión de despliegue.
Esto no elimina el debate cliente-vs-backend, lo enriquece. El eje de decisión ya no es solo ¿local o servidor? sino ¿dónde en el continuo cliente-edge-servidor tiene más sentido esta lógica específica?
En 2025, Fermyon fue adquirida por Akamai, la mayor CDN del mundo, para apostar por Wasm como runtime del edge computing. Cuando el mayor distribuidor de contenido del planeta mueve ficha así, el mensaje es claro: Wasm no es una optimización de frontend. Es infraestructura.
Lo Que Hice en DoctVault y FormatVault: Decisiones Reales
Este tipo de partición entre computación local y coordinación centralizada no es una invención propia. Es el mismo modelo que siguen herramientas local-first maduras como Obsidian, Linear o Figma en su modo offline: procesamiento e interfaz en el cliente, sincronización y estado compartido en infraestructura. La arquitectura híbrida no es un compromiso, es el diseño correcto para ese tipo de problemas.
Lo que sí puedo aportar desde mi experiencia concreta son las decisiones reales de qué fue al cliente y qué no, porque eso raramente aparece documentado.
Lo que migré al cliente:
Procesamiento de imágenes y PDFs (conversión, firma, unión, división, cifrado): computación pura sobre datos locales, sin estado compartido. Caso perfecto para Wasm y APIs nativas del navegador.
La cola de procesamiento con batching dinámico según dispositivo: esa lógica depende del hardware del usuario, no tiene sentido en un servidor que no sabe si el cliente es un iPhone o un desktop con 32 GB de RAM.
Renderizado, preview y firma táctil sobre canvas: requieren acceso inmediato al buffer en memoria. Un backend añadiría latencia de ida y vuelta inaceptable para una experiencia interactiva.
Lo que no migré al cliente:
Telemetría de uso anónima: necesito datos agregados de todos los usuarios para tomar decisiones de producto. Eso requiere un servidor.
Actualizaciones de la base de datos de amenazas de Brújula Security: la fuente de verdad de qué dominios son maliciosos tiene que venir de algún lugar con criterio editorial. El cliente consume esa base, no la genera.
El patrón es consistente: la computación es local, la coordinación y el conocimiento compartido requieren infraestructura.
El Árbol de Decisión Final
Antes de decidir si tu próxima funcionalidad vive en Wasm cliente, en un backend, o en Wasm edge, hazte estas preguntas en orden:
1. ¿Los datos que necesita procesar esta funcionalidad ya están en el dispositivo del usuario?
- Sí → Sigue al punto 2.
- No → Evalúa si el coste de transferencia justifica el procesamiento local.
2. ¿El resultado de la operación necesita ser verificado por alguien más aparte del usuario?
- No → Sigue al punto 3.
- Sí → Necesitas un servidor. Wasm cliente puede hacer el procesamiento intermedio, pero el resultado final pasa por infraestructura de confianza.
3. ¿La privacidad del usuario se beneficia de que el dato no salga del dispositivo?
- Sí → Wasm cliente es la arquitectura correcta. Documéntalo como decisión de diseño explícita, no como consecuencia accidental.
- No crítico → Evalúa coste de implementación vs. alternativa JavaScript. Wasm solo justifica complejidad extra si hay ganancia de rendimiento medible.
4. ¿La carga de trabajo es compute-bound o I/O-bound?
- Compute-bound (mucho cálculo sobre pocos datos) → Wasm brilla aquí. La ventaja de velocidad respecto a JavaScript es real y medible.
- I/O-bound (mucho acceso a disco/red con poco cálculo) → La ventaja de Wasm es marginal o nula. El cuello de botella no es el cómputo.
5. ¿Necesitas multi-threading real para el rendimiento?
- Sí → Verifica que puedas servir los headers COOP/COEP sin romper integraciones de terceros. Si no puedes, evalúa si Web Workers con message passing (sin SharedArrayBuffer) es suficiente para tu caso.
- No → Sin restricciones adicionales. Adelante.
Conclusión: Wasm No Es una Religión
La comunidad de Local-First y Wasm tiene una tendencia a convertir la tecnología en ideología. Todo al cliente, sin servidores, soberanía total. Yo comparto los valores filosóficos detrás de ese movimiento. Pero los valores filosóficos no diseñan sistemas. Las decisiones técnicas informadas sí.
Wasm 3.0 es un estándar maduro. WasmGC elimina uno de los mayores problemas históricos de tamaño de binarios. WASI convierte Wasm en un runtime universal que va mucho más allá del browser. El edge computing está apostando fuerte por esta tecnología con dinero real y workloads reales.
Pero la tecnología sirve al problema, no al revés. Hay cargas de trabajo donde Wasm en el cliente elimina el backend de forma legítima, mejora la privacidad del usuario, reduce costes de infraestructura y mejora el rendimiento simultáneamente. He descrito esas cargas arriba con ejemplos concretos de producción.
Y hay cargas de trabajo donde migrar al cliente con Wasm es una decisión arquitectónica errónea que vas a pagar con deuda técnica, problemas de consistencia, imposibilidad de verificación externa, y debugging más difícil.
El desarrollador que entiende la diferencia no es el que sabe usar Wasm. Es el que sabe cuándo no usarlo.
Y el sistema que funciona no es el más local. Es el que tiene cada pieza donde corresponde.
Wasm no elimina arquitecturas malas. Solo las hace más rápidas.
¿Has migrado lógica de backend a Wasm en el cliente en producción? ¿Cuáles fueron las decisiones más difíciles?
Computación Local vs. Coordinación Distribuida
La matriz de decisión, el árbol de decisión completo y el análisis del anti-patrón de este artículo están disponibles en PDF para consulta offline y referencia técnica.
📥 Descargar PDF: Computación Local vs. Coordinación Distribuida: WebAssembly
¿El fin del Backend?
Análisis de Arquitectura: WebAssembly y la Viabilidad de la Eliminación del Backend
Vídeos relacionados
Artículos Relacionados

Tu Navegador ya es un Servidor: IA Local sin Nube
WebGPU, Wasm y CRDTs permiten ejecutar modelos de IA y bases de datos en tu navegador. Sin nube, sin intermediarios. Tus datos permanecen bajo tu control.

El código de IA no se escribe, se hereda
La IA escribe rápido pero el mantenimiento llega después. Qué es la deuda de comprensión, qué dicen los estudios y cómo decidir antes de aceptar su código.

La Gran Ilusión del Prompt-to-App: Lo que nadie te cuenta
Prometen apps en 30 segundos, pero te dan fachadas vacías. Descubre la verdad técnica sobre el Prompt-to-App y las 7 preguntas para evitar desastres.
¿Te gustó este artículo?
¿Te ha resultado útil? Compártelo y suscríbete a nuestra newsletter para recibir más contenido sobre tecnología e IA.